
Practice Project: Checkpoint 1
Let's have a look at the dataset we are going to use for our practice project and apply our learnings from Checkpoint 1 to a real dbt project.
Part of the “Mastering dbt” series. Access to the full Study Guide. Let’s connect on LinkedIn!

Reviewing the documentation is essential to passing the certification. However, by applying our learnings to a real project, we expose ourselves to errors and learn how to debug them, which is one of the topics covered in the exam.
In this post, I am going to suggest a dataset that you can use to practice your dbt skills and define the practical tasks for Checkpoint 1. The idea is that, in each Checkpoint, we apply the learnings we gathered from the documentation to this project.
One thing to note: I am not going to give detailed, step-by-step instructions on how to do the tasks. If you took the dbt Fundamentals and the Certified Developer Learning Path courses and have reviewed the study notes for this Checkpoint, you should be able to do them. However, I will link to relevant documentation.
Table of contents:
The dataset for the practice project
Describing the data
There are several public datasets available online, however I wanted to find something that we could scale up in future Checkpoints to practice dbt’s more advanced features, like incremental materialisations, for instance.
Therefore, for this project, we are going to use the dataset created by Leo Godin on Medium. It is available as a public table on BigQuery, where new records are added daily. You can also set up his dbt project and generate the tables.
For the initial Checkpoints, though, we are going to use static data for simplicity.

The dataset simulates a situation in which employees of different companies can order products. For this practice project, we are going to use the following sources:
Companies_base: a database of companies with their slogan, their purpose, and the data they were added. Companies added from 2020-2025, amounting to 12,661 rows.
Employees_base: a database of employees with their company_id and other demographic information. Employees added from 2020-2025, amounting to 10,002 rows.
Fake_personal_info: additional information on the employees. Employees added from 2020-2025, amounting to 10,000 rows.
Enterprise_orders_base: a database of orders placed with the respective employee_id, product_id, and number of items. Orders from 2023-2025, amounting to 4,768 rows.
Products_base: a database of products with name, price, category, and date added. Products added from 2020-2025, amounting to 10,000 rows.
Obtaining the data
If you want to use the same dataset as me, you can download the csv files here.
In future checkpoints, we are going to pull live data from his public dataset on BigQuery. If you want to do this now, his public warehouse is “leogodin217-dbt-tutorial”.
Of course, you are free to use your own dataset, but the tasks I will describe in each checkpoint may be specific to this dataset.
Tasks for Checkpoint 1
In this Checkpoint, we will focus on:
Uploading the sources to the cloud warehouse
Setting up a new project on dbt
Defining basic project and source configurations
Creating our first models to clean the sources
Committing the new models to the main branch and building our project
At the end of this checkpoint, our DAG will look like this:
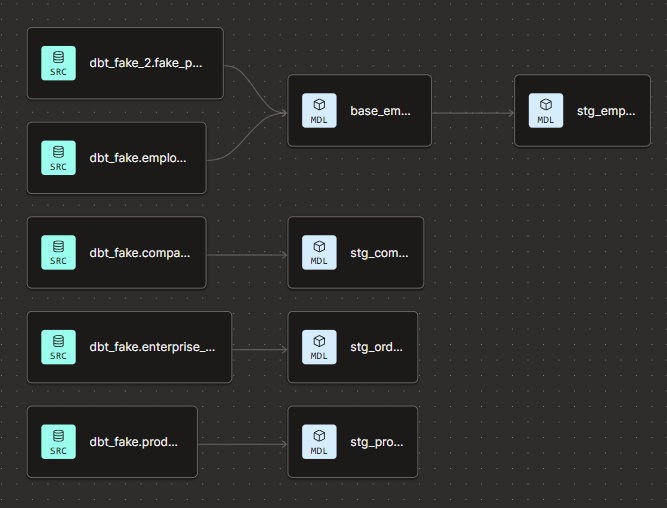
1) Uploading the data to the cloud warehouse
In this practice project, I am going to use BigQuery because it offers the most generous free tier and is fairly easy to set up. You are free to use whichever platform you prefer, and dbt offers documentation on how to set up connections with several options.
Ideally, you should have all the tables under one schema. You will notice I ended up with two schemas because that’s how it came from Leo Godin's dbt project.

2) Setting up a new project on dbt
At this stage, you will need to give the project a name and set up your repository on GitHub. Finally, you will set up the connection to the cloud warehouse.
After you create your repo, ensure you give dbt access to it on Profile Settings > Configure Integration on GitHub.
If you don’t know your way around GitHub, I suggest you check out the initial chapters of this Pro Git book.
3) Defining basic project and source configurations
At this stage, we haven’t reviewed the documentation for the dbt_project.yml and sources.yml files. However, in this Checkpoint, we are going to add basic configurations.
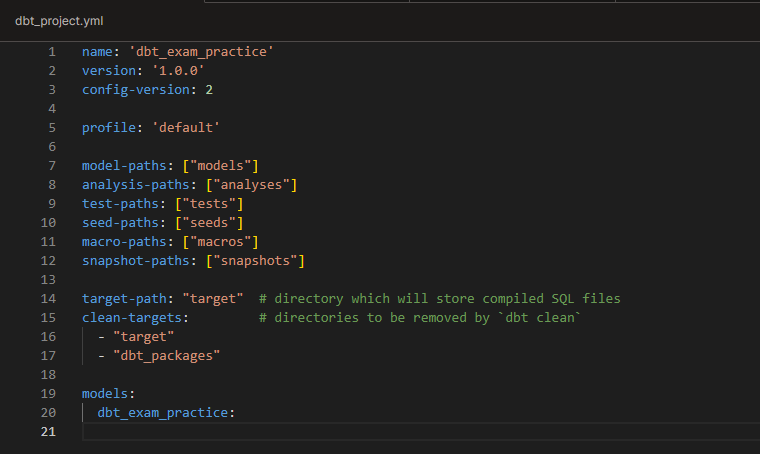
For the dbt_project.yml, I focused on removing the comments, as recommended by the essential project checklist, and changing the project name. I have not added materialisations yet because we’re only doing staging models, and the recommendation is to keep them as views, which is the default config on dbt.
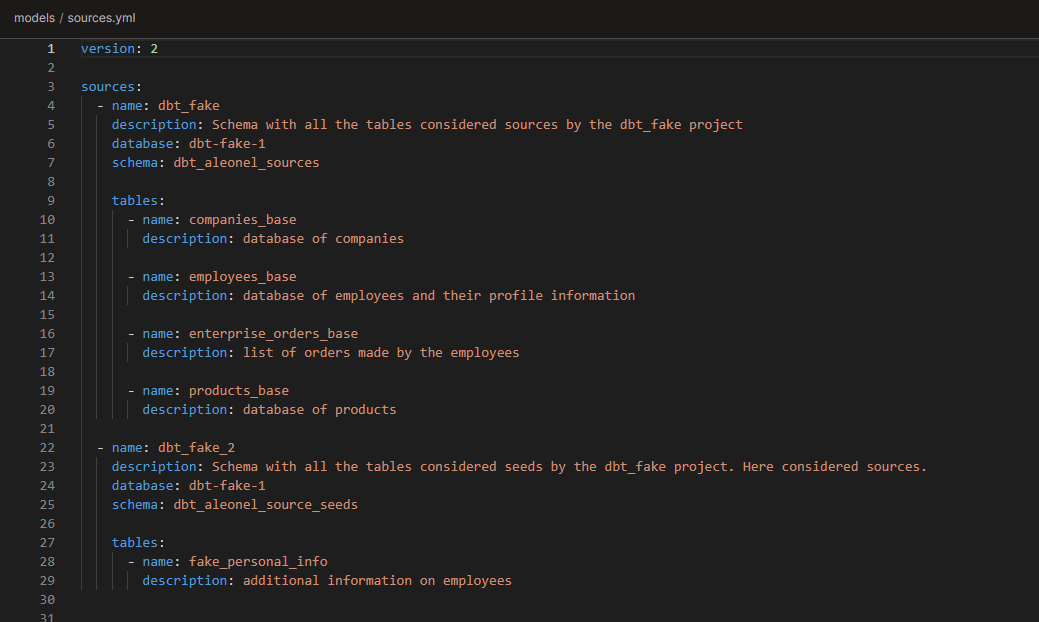
For the sources, I added the compulsory configs, plus some descriptions. Again, note that if you’re using the csv files, you should only have 1 schema.
4) Creating our first models to clean the sources
For this Checkpoint, we are going to create our staging layer following the principles of modularity and DRY. Don’t forget to delete the example folder under models.
For some steps, dbt packages would come in handy, but we are going to add them in future Checkpoints.
In this study note, we learned that the staging layer should be reserved for basic cleaning operations like renaming columns, type casting, removing nulls, etc. You will also notice that for the employees table, I had to create a base model to join two sources.
Below are the models I created and the cleaning operations I performed. They are just suggestions. You can do whatever you find necessary, as long as you follow the recommendations linked above.
stg_companies.sql
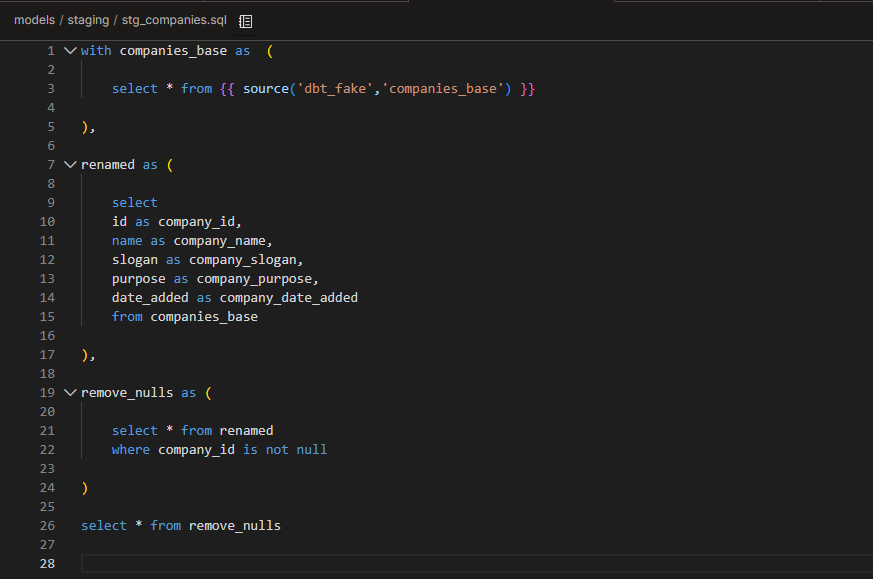
Renamed columns to add the “company_” prefix
Removed null company_ids
Casted company_date_added as date
Checked for overly long company names, slogans, or purposes.
stg_orders.sql
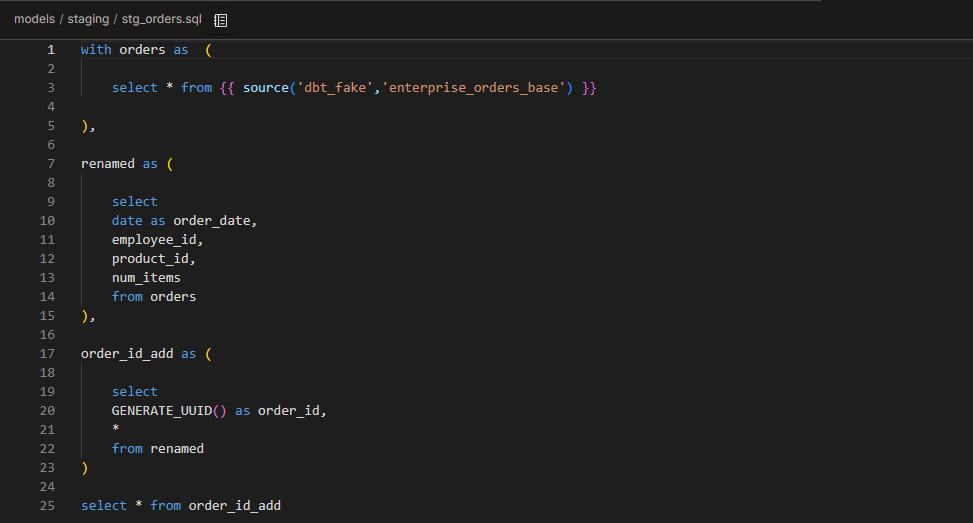
Renamed date to order_date
Added order_id. For now, I am using generate_uuid, but when we introduce packages, I will create a surrogate key with dbt utils.
stg_products.sql
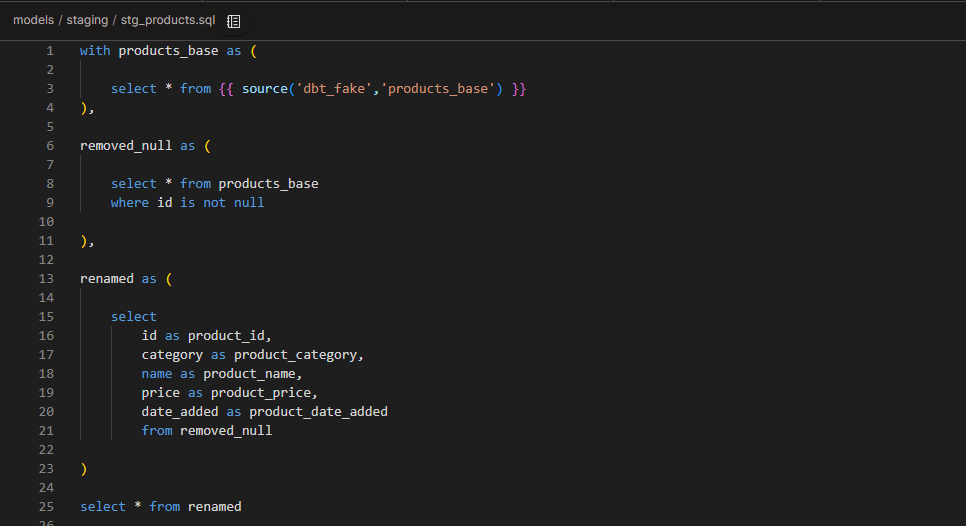
Removed null ids
Renamed columns to add the “product_” prefix
base_employees.sql
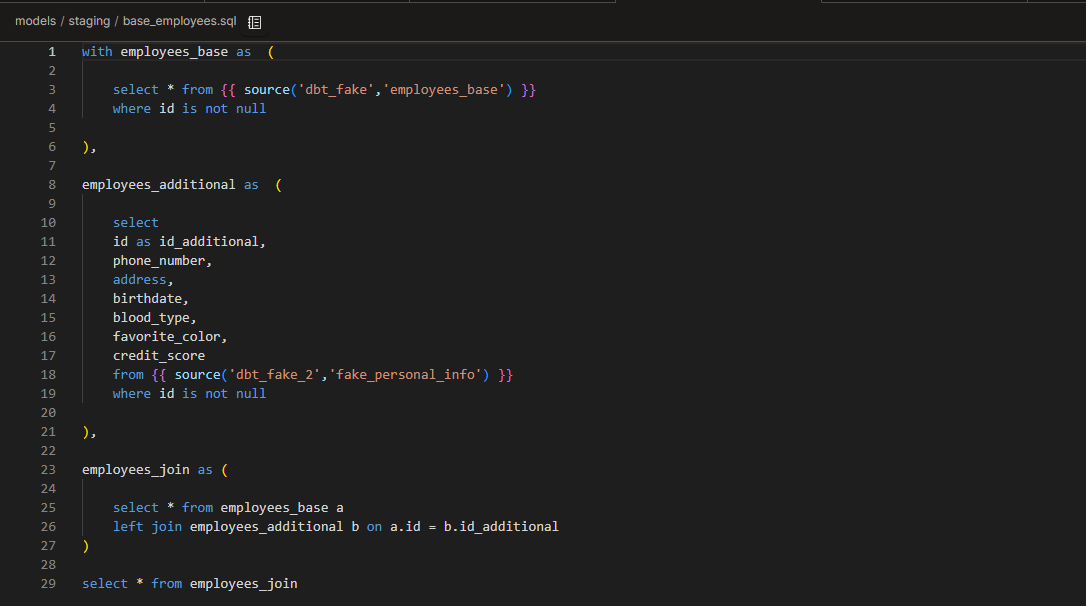
We have employee information in 2 different tables. These tables will never be used in isolation, so it makes sense to join them before cleaning them. Following the modularity principles, this step should be done in a base layer before staging.
stg_employees.sql
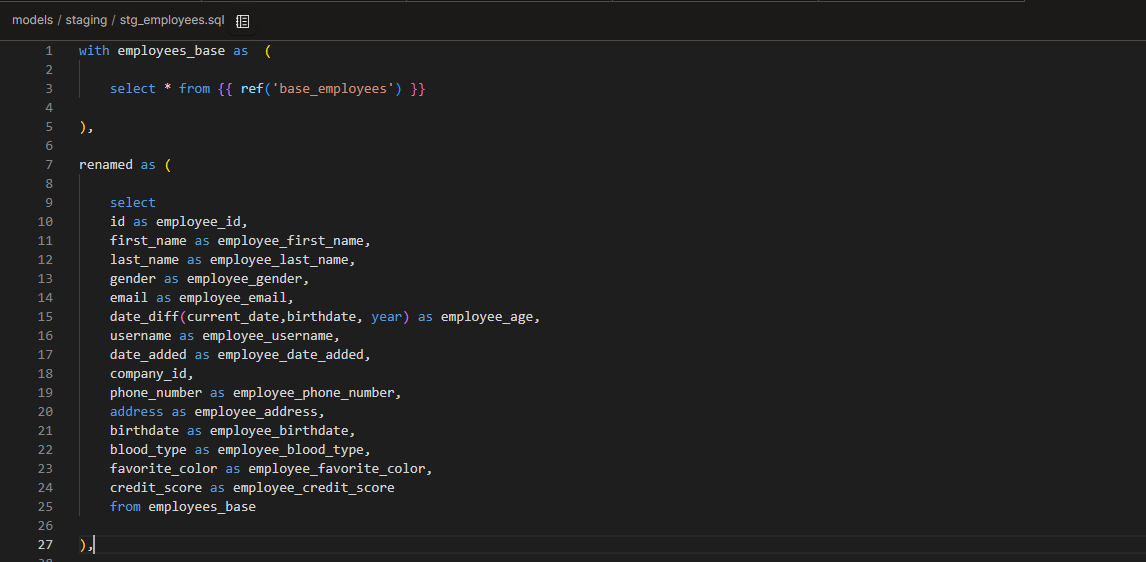
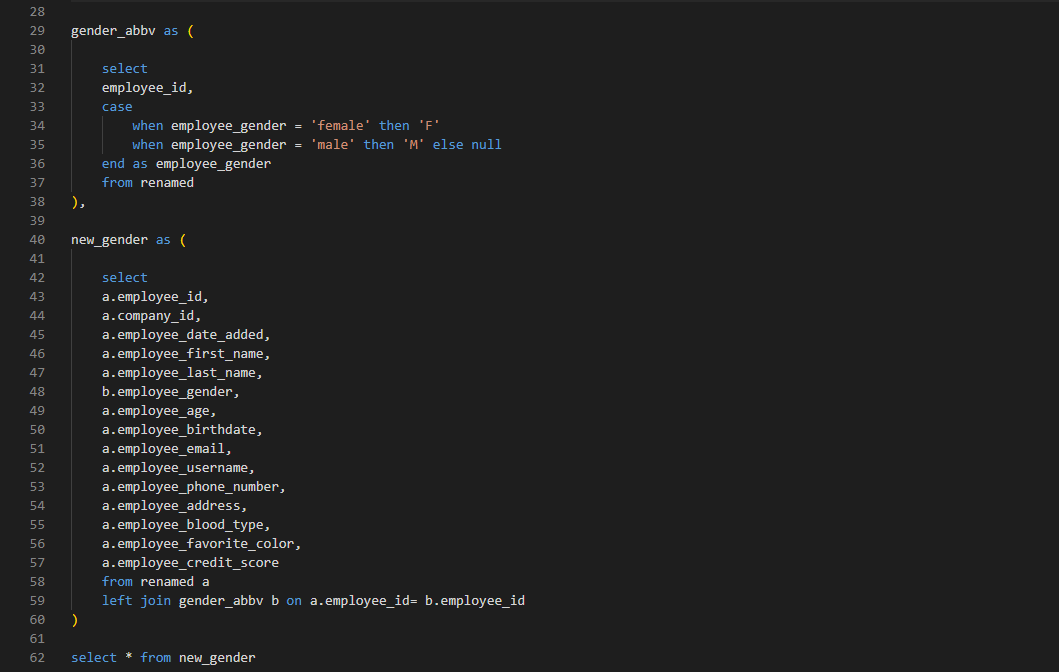
Renamed columns to add the “employee_” prefix
Removing the extra id that came from the join
Checked for nulls, invalid birthdates or blood types, etc
Replaced the age column with a calculated column based on birthdate. The original age column was incorrect.
Abbreviated the gender column
5) Committing the new models to the main branch and building our project
Your project should have been initialised in the main branch. As per the Direct Promotion branching strategy, we are going to commit these changes to a new feature branch.
After that, you should create the pull request on GitHub and merge these changes into the main branch. I did not use PR templates yet, I’m leaving it for future Checkpoints.
In order to build the models, we need to set up our environments. Currently, we only have a Development environment. We are going to create our Staging (not necessary for now, just for practice) and Production environments.
For the QA environment, we will have it as a staging type and, as such, it serves the purpose of seeing the changes made to the data on a separate dataset in the warehouse and within the UI. In the future, we will create CI/CD jobs to make this happen. Link this environment to a separate _qa schema and the main branch.
For the Production environment, it is obviously of Production type and I linked it to a _prod schema and the main branch.
Please note that these target schemas require a profiles.yml file that we won’t go into yet. For now, our production data will be written into a default schema.
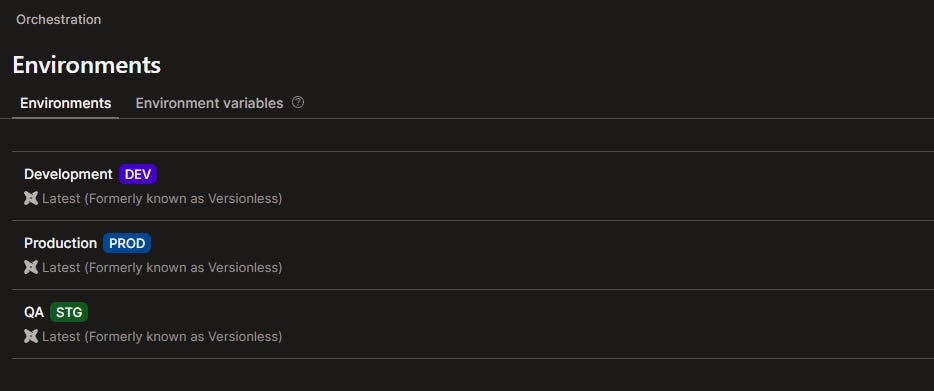
Now, we can build our models using the “dbt build” command. You can also run the command “dbt build --select stg_*” to run only the staging models, if you consider the base model for employees to be unnecessary.
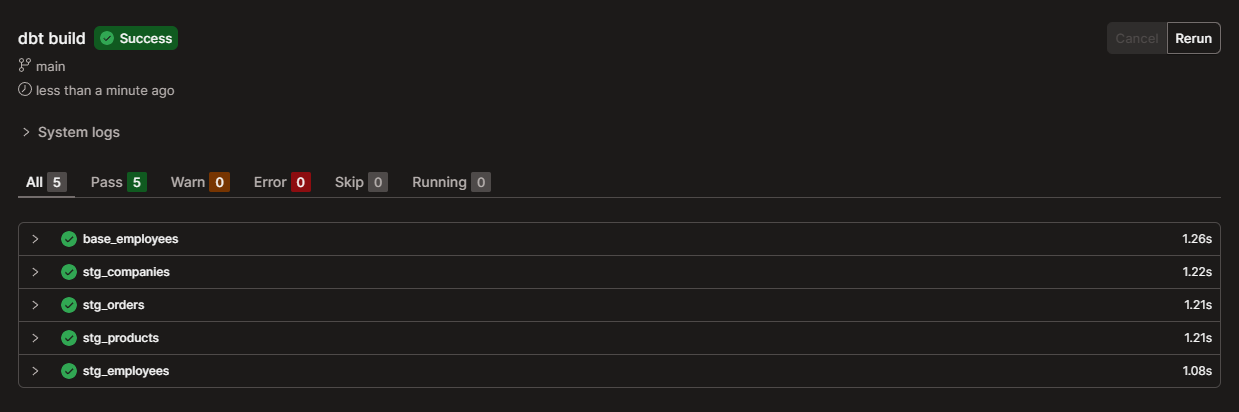
After that, our views should appear in the warehouse.

We have completed Practice Project tasks for Checkpoint 1! We will now move to Checkpoint 2: the basics where we will review documentation on DAG best practices, dbt_project.yml and sources configurations, materialisations, and how to read the logs.