
How to structure your dbt projects
Recommendations for filing & naming conventions, materialisations, and operations for each layer of the DAG
Part of the “Mastering dbt” series. Access to the full Study Guide. Let’s connect on LinkedIn!
Notes from this dbt blog post.
In the Your Essential dbt Project Checklist study notes, we covered some of the principles to be followed when structuring your project. It covered mainly the dbt_project.yml file, DAG structuring, and coding.
We are now zooming into the 3 layers of the DAG - staging, intermediate, and marts - and defining filing & naming conventions, materialisations, and operations for each layer.
Overarching principles when designing layers
As your data flows down the stream, it should move from source-conformed to business-conformed. Data is source-conformed while it is shaped by external systems. As it goes through the staging, intermediate and marts layers, it starts to become shaped by the needs, concepts and definitions that we require.
Another important foundation to keep in mind when thinking about your project is to start simple and only add complexity if necessary. Some of the recommendations that will be covered here are not necessary for every project. Or some projects will need to have extra steps to make it easy to debug and understand. Regardless, the most important thing is to think intentionally and document your project thoroughly.
Also, the author clarifies that although we are following the order of the DAG here, that is not how you would design your project. In a real-life scenario, you would first align with stakeholders on what the output should be. Then, you would identify the tables and the logic necessary, and build the SQL to achieve it. Then, you would break the SQL up into layers.
I don’t know how much of a rule that is, as I have never used dbt in a working environment, but I found it interesting to know that you’d start with a traditional SQL script. This is probably why refactoring SQL is a topic of the exam.
Staging models: preparing the building blocks
Filing & naming conventions
Think of your folders as an organisational method, but also as a means of selection for dbt commands. For instance, if all models in the stripe folder will likely be run together at all times, you can use “dbt build —select staging.stripe+”
With that in mind, it makes sense to group your staging models by source system, as you will likely perform commands on them together.
Don’t split them up by business area here, it is too early and your staging operations will depend more on the source system.
Naming conventions: stg_[source]__[entity]s.sql with double underscore to account for two-word names
(eg. stg_google_analytics__campaigns)
Models
Transformations:
Renaming, type casting, basic computations (eg. cents to dollars), categorising (using case when, for instance).
Having these types of transformations done as early as possible is great to keep your code DRY.
No joins, except for when a source is only useful if joined to another source, like unioning customer lists from different e-commerce sources. In this case, we’d have a base model for cleaning and the join would happen at the staging level.
No aggregations at this stage to avoid losing useful information.
Materialisation:
Materialised as views, as they are not intended to be final artifacts.
A consideration about this: if there’s an error in a view, this error will be flushed down to the first table created (eg. marts) and it’s difficult to understand where the error is coming from. When debugging, if an error is confusing, turn all models into tables so the warehouse throws the error where it’s occurring.
Other recommendations
Keep a 1-to-1 relationship with the sources.
The source macro should only be used here. After this layer, we will use the ref function.
Use the codegen package to generate useful code, like listing all sources/models with standard config blocks, or code selecting all source tables and their individual columns.
Create a model/utilities folder for exploratory queries, queries generated from macros that will be reused, etc.
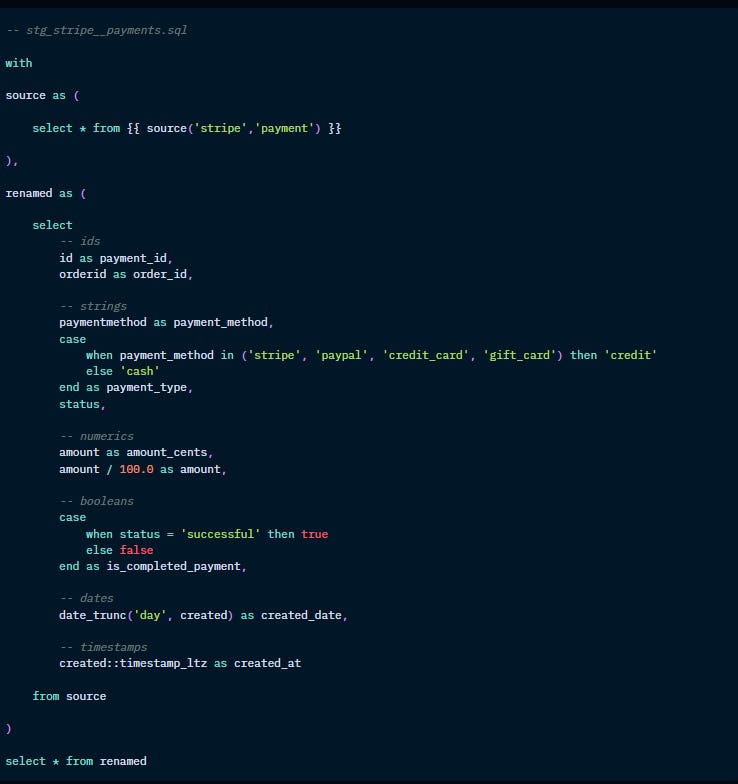
Intermediate models: purpose-built transformation steps
Filing & naming conventions
You could start creating subdirectories based on business groupings (finance, marketing, etc) here. But only do it if necessary. If two marts can pull from the same table, allow that.
Naming conventions: int_[entity]s_[verb]s.sql
(eg. int_finance_funnel_created.sql)
Models
Transformations:
Examples: join stg models to generate a mart, re-aggregations (like number of orders per payment method), isolating complex operations (like pivotting or unpivotting)
Materialisations:
Materialised as ephemeral. This is the author’s suggestion, however, digging deeper into ephemeral materialisations, you quickly realise that it has some limitations. You cannot select from these models, they don’t support model contracts, and are harder to debug, amongst other things. It does save space in the warehouse, but evaluate if this economy is worth it.
An alternative is to materialize them as a view in a custom schema outside your main production schema and with specific access permissions.
Other recommendations
Don’t expose intermediate models in main production schemas as they’re not a final output.
Up until this layer, you want your DAG to be narrowing down from multiple sources to more streamlined resources that are clean, normalised, and with the added business logic. So the marts have clear and easily debuggable resources.
It is normal to have multiple inputs to an intermediate model, but be careful with multiple outputs (unless these are marts).
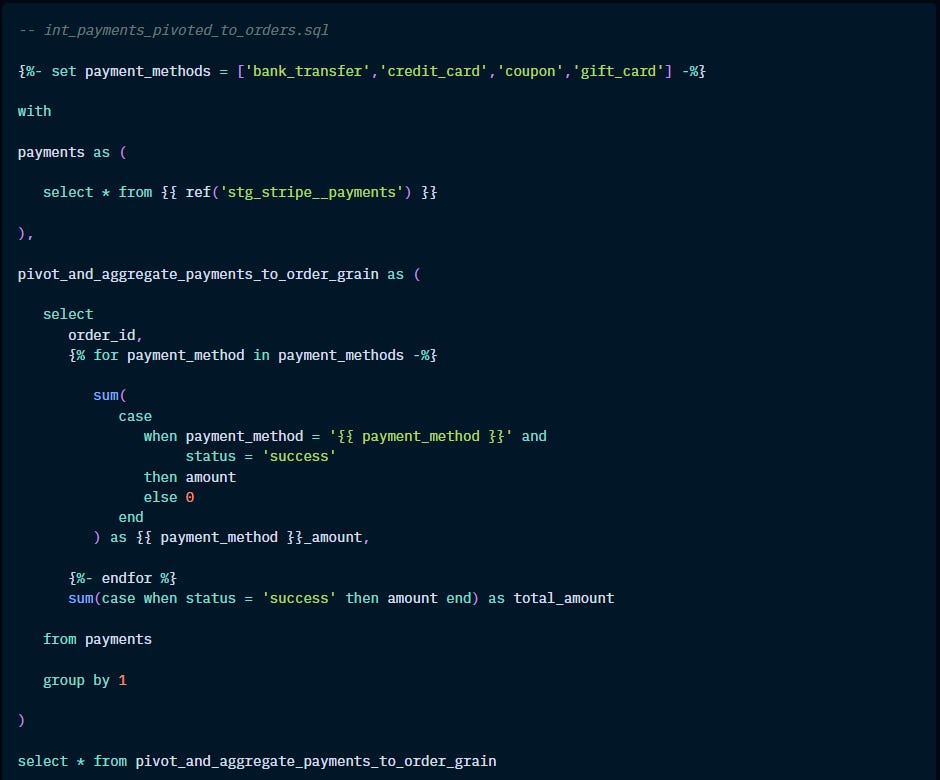
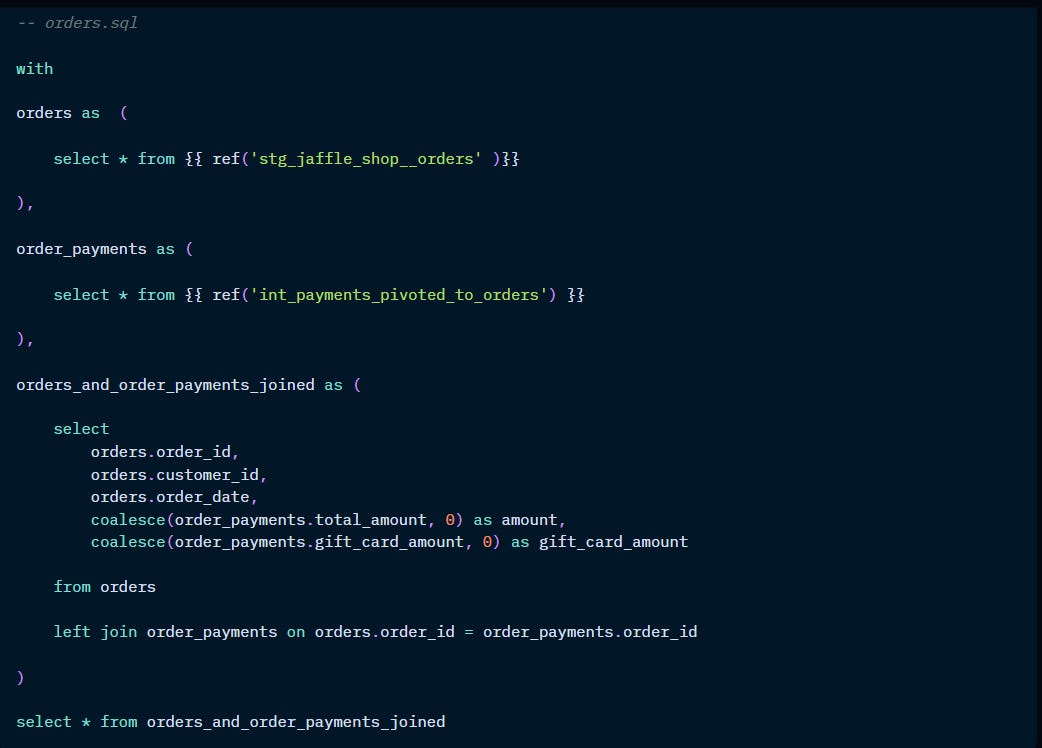
Marts: business-defined entities
Filing & naming conventions
Subdirectories by department or area of concern. But don’t add unnecessary subdirectories.
Assess the need for different marts. Typically, for instance, a table describing order attributes can be used for both finance and marketing. There are exceptions, of course.
Naming convention: by the entity that is being described.
(eg. orders.sql, customer.sql)
Models
Transformations:
Marts are entity-based: think about what represents each single row in your table. For example, the main entity is order (each row is an order id) with all its attributes (eg. order_date, order_status). You can also bring information from other entities (like user_gender).
Don’t join too many tables in a mart: consider adding an intermediate model if you find yourself doing too many joins in the mart stage.
Pulling data from a mart into another mart: if you’re trying to save on computing, it makes sense to bring previously created logic from another mart, rather than repeating the code. However, be careful with circular dependencies.
Metrics: if you start digging into a “per_day” view, you’re moving past marts into metrics (eg. user_orders_per_day)
Materialisation:
Materialized as tables or incremental models: these tables will be queried by dashboards, so they need to be written into the warehouse. Incremental models are necessary when run time is too great; don’t use them unnecessarily, as they add complexity.
Other recommendations
Fan out: tables are wide and denormalized. The DAG is narrow up until here. After this, creating more tables makes more sense than complex computing as storage is cheaper than computing.
The rest of the project:
yml files:
Have one config file per folder (_[directory]__models.yml) and a sources.yml per staging folder (_[directory]__sources.yml). Start with the underscore so they are sorted to the top.
Don’t have a single config file for the entire project. But also, there is no need for one config per model.
On dbt_project.yml, you can set configs at the directory level to keep it simple. Define schemas and materialisations for an entire folder, for example.
Prefer folder-level configs to tags to avoid having to tag every single model and end up with multiple tags.
Seeds:
Don’t load data from source systems into seeds. Seeds are for lookup tables that are helpful for modelling, but don’t exist in any source systems.
Analyses:
Queries that you don’t want to build into the warehouse. Useful for queries that are part of the audit helper package.
Tests:
Stores singular tests, although most of these are covered by the dbt-utils and dbt-expectations packages.
Snapshots:
For creating slowly changing dimensions, known as Type 2 or CD2.
Macros:
Recommend writing a _macros.yml to document the macros.