
Your Essential dbt Project Checklist
Best practices to build an efficient, maintainable and streamlined dbt project
Part of the “Mastering dbt” series. Access to the full Study Guide. Let’s connect on LinkedIn!
Notes from this dbt blog post.
The original blog post focused on what to check when auditing an existing project and, therefore, mentioned some functionalities that were quite advanced.
As we are still in the first checkpoint, I decided to trim the post down a bit to focus on the more basic steps you’d need to ensure to take when building your first few projects.
However, I did include the more advanced topics at the bottom of this post as I believe it can be useful to familiarise ourselves with them at this stage. These topics will be covered more in-depth in future checkpoints.
The idea is to help you get a head start on your dummy project, following the correct principles of modularity and project building.
Setting up your dbt_project.yml:
The dbt_project is a required file for all projects and contains a set of operational instructions for your project. A more in-depth documentation about this file will be reviewed soon, but these are some initial best practices:
Init project settings
Rename the default ‘my_new_project’ to your project’s actual name
Remove init comments: This file initialises with several default comments that should be removed to reduce clutter.
Unnecessary configurations
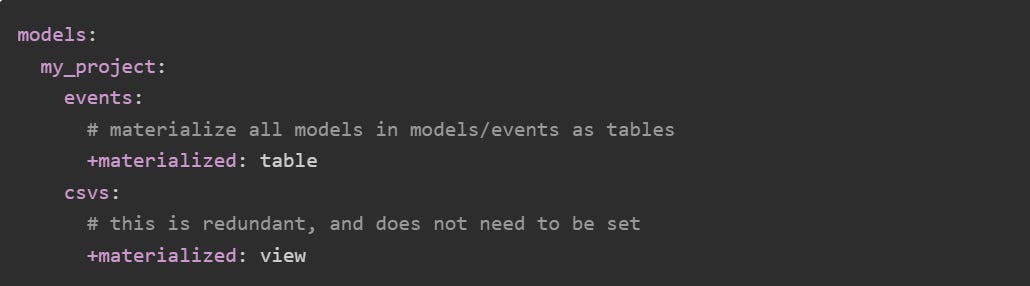
No need to define View materialisations: when a table materialisation is not defined, it defaults to View. Therefore, View materialisations add unnecessary clutter to the file.
Consider at which level materialisations should occur: they can be defined at the project, folder, or model level. As an example, if an entire folder of models needs to be materialised as Tables, instead of adding this config to each individual table, you can set it up for an entire folder.
Structuring your DAG:
Building an efficient DAG:
Filter unnecessary data as early in your pipeline as possible to avoid wasting processing time and reduce clutter.
There should be no repeated logic across the models. Move repeated logic upstream or to intermediate models that can serve multiple models.
When doing joins using multiple columns, condense these columns into a single column (a surrogate key column, for instance) upstream for simpler joins down the line.
Do you have staging and marts models using the correct prefixes? We covered naming conventions in the Data Modularity post.
Don’t entangle your DAG:
Ensure there are no joins to your source tables at intermediate level and downstream. Only staging or base models should pull directly from raw data.
If two sources need to be joined together before staging level, do it in a separate base model so the principle of one source → one staging model is followed.
At the intermediate layer, there should be no joins between staging and intermediate models. Add another intermediate model to avoid this or rethink your strategy.

Avoid “bending connections”: models should not join with other models in the same layer. An extra base model or a rethinking of the strategy should address this.

Don’t end up with multiple layers of dim/fact models. If necessary, move some transformation to the BI tool or upstream. Your project should have a clear endpoint.

Code:
Ensure your coding is optimised with window functions and aggregations to improve run time and readability.
Make sure you always query sources using the ref function, instead of querying raw tables. These sources need to be defined in the sources.yml file.
Write code/CTEs that follow modular principles.
Make use of jinja/macros to reduce repetitiveness.
Add relevant in-line comments to clarify complex logic in the models or macros.
For incremental models, ensure they use unique keys and the is_incremental() macro.
Packages & Macros
Is dbt_utils being utilised? Double-check if any of its macros could be useful to improve your project and/or make it more DRY - study notes on DRY principles here.
When creating macros, ensure they are clearly named to represent their function in the project.
Ensure all installed packages are up to date on their versions.
Testing
Implement relevant testing across the project to ensure basic assumptions are met (like no nulls or expecting a particular data type in a given column).
The suggested rule of thumb is to have at least a not_null/unique test on all primary keys.
Ensure your testing assumptions follow business logic and your understanding of the sources.
Version control: ensure to implement a pull request strategy for modifications and the use of a PR template.
Documentation
Implement documentation for your project that facilitates onboarding and an easy comprehension of what your models achieve.
Ensure models have descriptors in the sources.yml file.
Complex logic and transformation should also be described and easily accessible.
If you need to add column-level descriptions, make use of code blocks.
Jobs
Set up jobs that make sense with what your project is trying to achieve.
Ensure the frequency of the runs syncs up with how often your data is updated so as not to waste runs on data that hasn’t been updated.
Evaluate your models’ running time: do you have a modelneck (a model that significantly increases overall running time)? Is it worth re-evaluating your model strategy (for instance, changing a model to incremental)?
Ensure you are using the latest version of dbt and that your jobs are inheriting the version from the environment.
Further down the line:
These are more advanced functionalities to audit in a more established project. We’ll glance over them here but they will be covered in depth in future checkpoints.
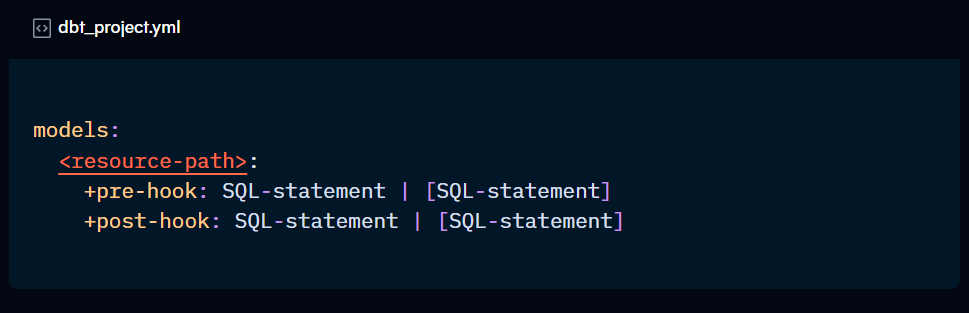
Using post-hooks to grant permissions
Post-hooks are snippets of SQL code that run automatically after a model has been run. They can be defined in the model itself or the dbt_project.yml file, and are then called by the model.
The suggestion is to use this functionality to run a command that grants permission to the relevant collaborators every time the models are run. This will ensure that permissions are maintained even after changes are made.
Utilizing tags in your project
Tags are a way of regrouping specific models, seeds, sources, queries, tests, and more. This way, you select a specific tag (or a combination of tags) and apply an operation to this grouping.
Use tags for models and tests that fall out of the norm with how you want to interact with them. They can be defined at folder level to avoid repetition, if relevant.
For example, tagging ‘nightly’ models makes sense, but also tagging all your non-nightly models as ‘hourly’ is unnecessary - you can simply exclude the nightly models.
Check to see if a node selector is a good option here instead of tags.
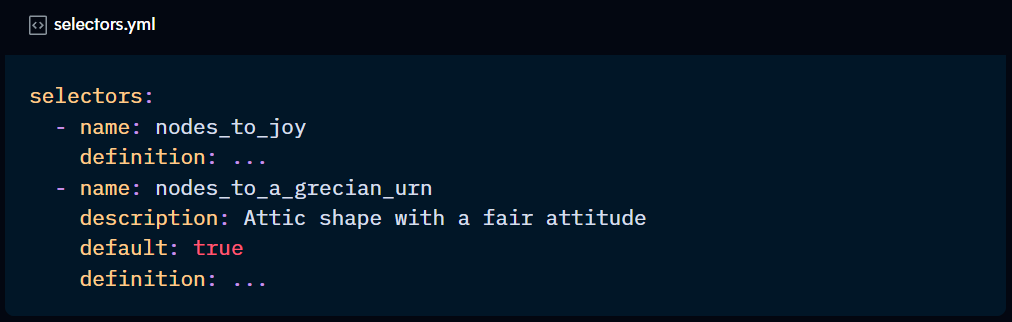
Using YAML selectors
Another way to facilitate custom selections is to define them in a selectors.yml file and call them using the --selector command.
Implementing Source freshness?
In your sources file, you can define how up-to-date the data for a particular model needs to be to be considered fresh. With that configuration, when you run the source freshness command, you can have an overview of whether your data is fresh or not.
This config is important to ensure that you are meeting the service level agreement (SLA) of your company and that the users are looking at the data they want to see.
Version control
Besides the pull-request strategy on git, you should also consider having version control configs in your models’ setup. This will be covered in future topics.
Jobs
Consider implementing full refreshes on production data at a frequency that makes sense for your needs.
Set up a Continuous Integration (CI) job for git-based projects.
Consider setting up notifications for failed jobs.