
Setting up and maintaining Snapshots
Understanding Snapshot strategies and how to set them up.
Part of the “Mastering dbt” series. Access to the full Study Guide. Let’s connect on LinkedIn!
Notes from the Snapshots, Snapshot Properties, Snapshot Configurations, and dbt snapshot command documentations.
We covered Seeds in the previous post and we are now moving on to another dbt resource: Snapshots.
So we can understand the role of Snapshots, we first need to clarify what SCD2 stands for. After that, we will go into properties, configurations, and the dbt snapshot command.
Table of contents:
Understanding SCD2 and Snapshots
SCD stands for Slowly Changing Dimensions and is a concept to track changes in dimension data over time. For example, when a customer changes their address or a product changes its category.
There are several types of SCDs (Type 0 to Type 7), but the most common ones are Type 1 and Type 2.
An SCD2 table inserts a new record every time a value is changed, so you can track attributes over time. Snapshots implement SCD2 to create a table that tracks changes.
Snapshots become warehouse objects and can also be referenced by other models using the ref function. The command should also be run on a schedule to record changes effectivelly.
Finally, Snapshot properties are declared within a properties.yml file, allowing you to define both the snapshot configurations and properties in one place. It is recommended to save this file in the “snapshots” directory.
Snapshot properties
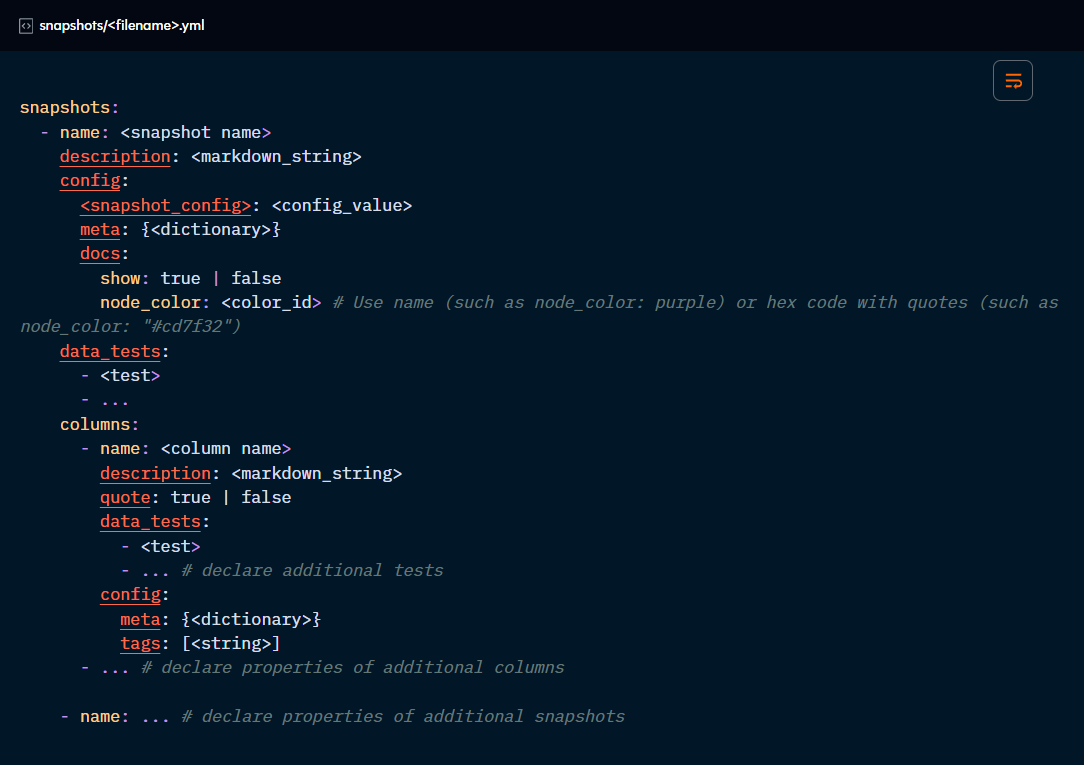
For tables and columns:
description: sets descriptions for documentation purposes
config: enables configurations to be added to the properties file.
data_tests: enables configurations for testing purposes.
For tables only:
docs: defines whether to show the resource in documentation and what colour the node should be in the DAG.
For columns only:
quote: disables or enables quoting of column names.
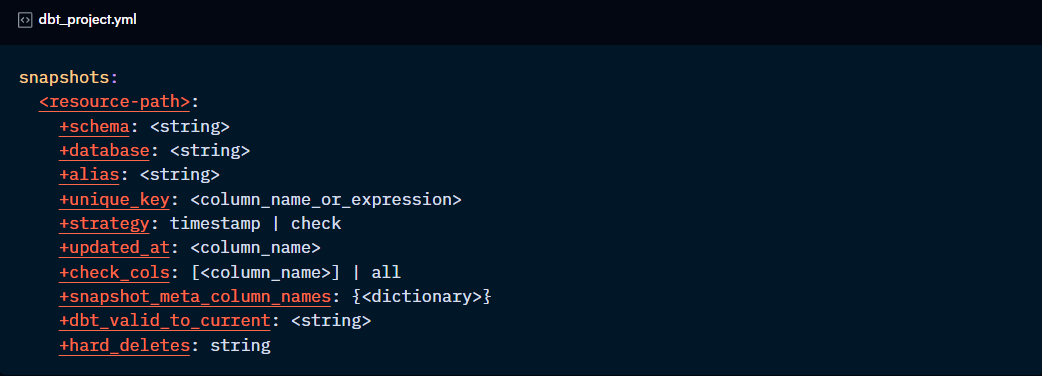
Snapshot configurations
Snapshot-specific configs:
Defining your Snapshot strategy:
The key config is “strategy” as it will define how dbt knows a row has changed. There are two types of strategies:
timestamp
Uses an “updated_at” field to decide if the row has been updated since the snapshot was last run. If dbt detects a new update, it adds the record to the table. This is a good strategy because it has a simple setup and isn’t affected by new or deleted columns.
check
When you don’t have a reliable “updated_at” column, use this strategy to compare historical column values to the current ones. It requires the config “check_cols” with a list of columns to compare, like [”name”, “email”]. For a large number of columns, consider using a surrogate key.
Other Snapshot configurations:
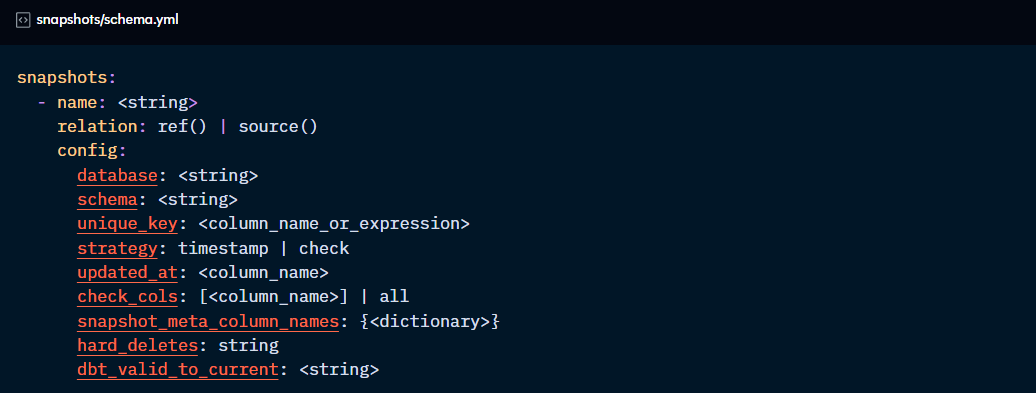
relation: use a ref or source function to define which table should be snapshot. If not set, dbt will take the target database and schema as well as the name of the snapshot for a table name. dbt recommends to use a staging model that’s already been cleaned rather than the raw data.
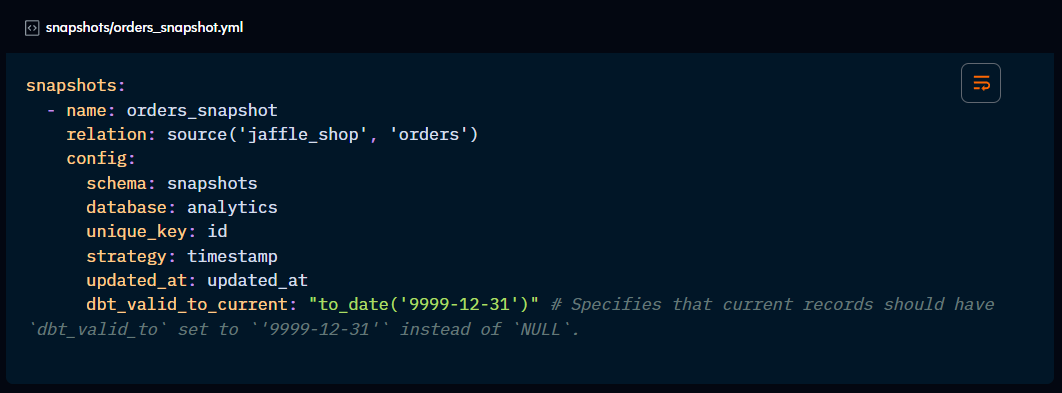
database/schema/alias: sets a custom database/schema/table name for the resource. dbt recommends building snapshots in separate schemas with special permissions so they don’t get accidentally dropped as they cannot be rebuilt.
unique_key: the column name that identifies each record.
updated_at: column that denotes the timestamp of changes made to the row (for timestamp strategy)
check_cols: column(s) touse for historical vs. current comparions (for check strategy)
snapshot_meta_column_names: allows you to set custom names for the metadata columns in the Snapshot. The default values are below:

dbt_valid_to_current: sets a custom date for the dbt_valid_to Snapshot column. By default, this value is NULL and, if updated, only current and future records are updated.
hard_deletes: defines what happens to rows deleted from the source. By default it is set to “ignore”, but it can also be “invalidate” which sets “dbt_valid_to” column to current date for those records, or “new record” which adds a new row for them with an extra “dbt_is_deleted” column.
General configs:
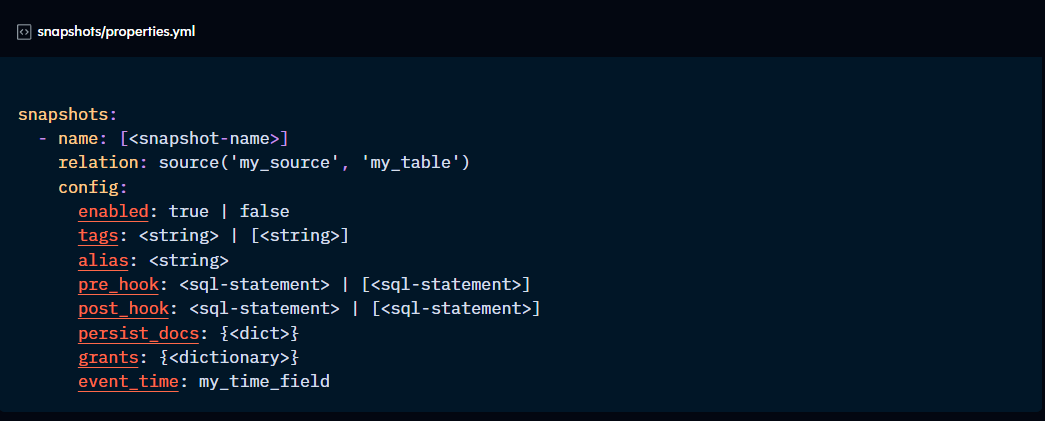
enabled: if set to False, dbt does not consider this resource part of the project.
tags: add common tags to resources to apply commands to all in one go using the “tag:” method.
pre-hook / post-hook: adds SQL statements that are run before or after the seed.
persist_docs: persists column and relation descriptions in the database.
grants: manages access to datasets. To be covered in future Checkpoints in more detail.
event_time: for seeds that track events, it defines the column where the time of the event lives for incremental materialisation, “--sample” flag, and CI/CD purposes.
The dbt snapshot command
The “dbt snapshot” executes the snapshots stored in the snapshot-path of your project.
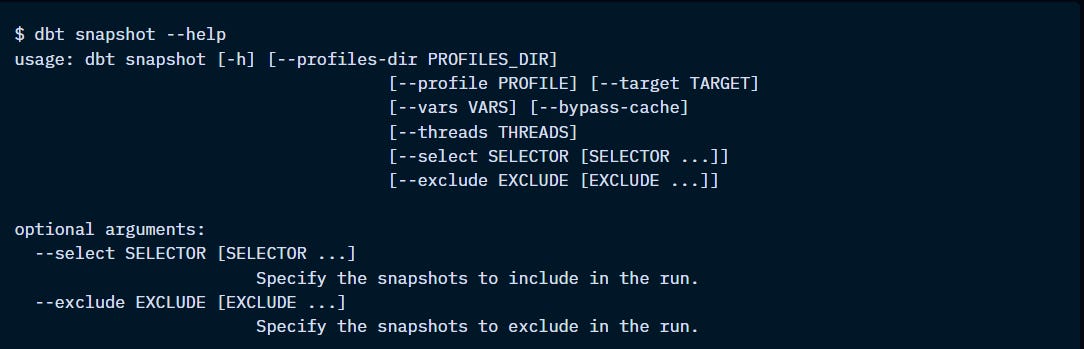
On the first run, dbt will add all the records with the additional metadata snapshot columns. On subsequent runs, it will check what records have been changed or added, according to the chosen strategy, and will add them to the snapshot table.
It is also important to note that while dbt will add new columns to the snapshot table, it will not remove columns deleted from the source. It also does not reflect changes in data types.