
A deep dive into Seeds
Definition, properties, and configurations for Seeds and the dbt seed command.
Part of the “Mastering dbt” series. Access to the full Study Guide. Let’s connect on LinkedIn!
Notes from the Seeds, Seeds Properties, Seeds Configurations, and dbt seed command documentations.
Seeds are .csv files with static data that can be loaded into the data warehouse using the “dbt seed” command.
You should not load raw data as a seed just because it is in .csv format. Typical examples of seeds include a list of countries and their two-letter codes, a list of emails to be excluded from analysis, or a list of account IDs.
Seeds are version-controlled and code reviewable. They can be referenced with the ref function, similarly to models, and live in the seeds directory.
Table of contents:
Seeds properties
These properties can be defined in any .yml file, but it is recommended to create a properties.yml file in the same directory as the seeds.
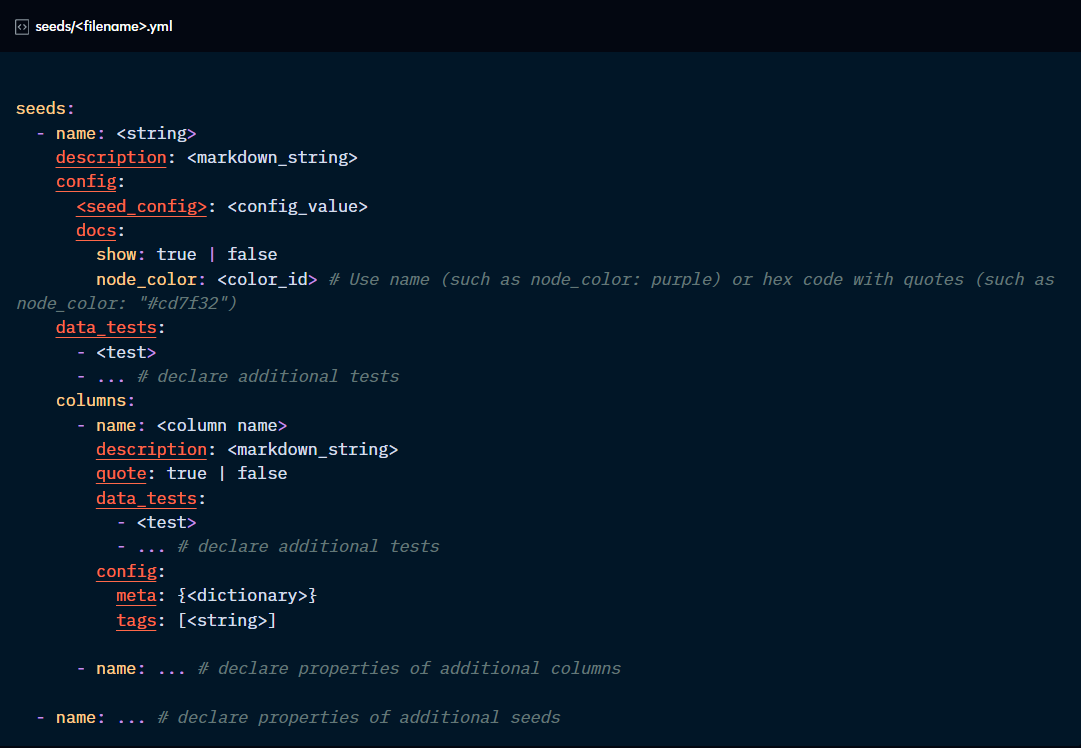
For tables and columns:
description: sets descriptions for documentation purposes
config: enables configurations to be added to the properties file.
data_tests: enables configurations for testing purposes.
For tables only:
docs: defines whether to show the resource in documentation and what colour the node should be in the DAG.
For columns only:
quote: disables or enables quoting of column names.
Configuring seeds
Seeds can be configured in the dbt_project.yml file, in a dedicated properties.yml file, or in the seed itself using the {{ config }} block.
Seed-specific configs:
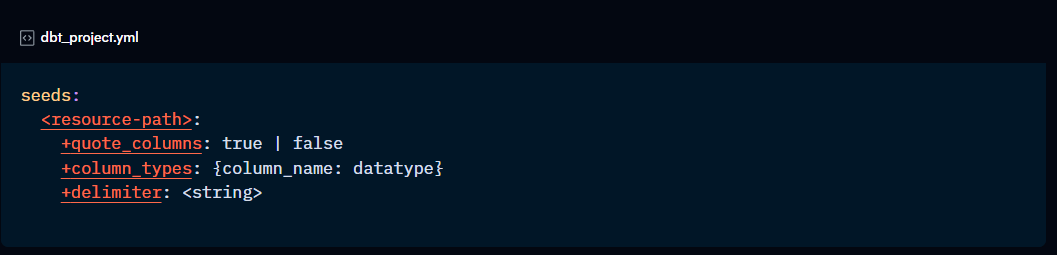
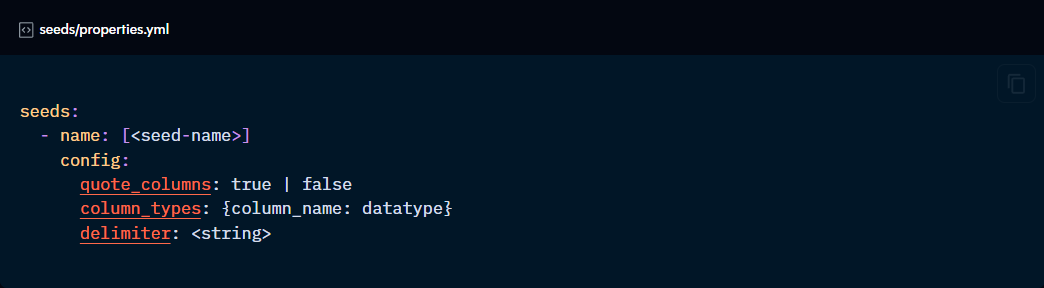
quote_columns: True | False (optional)
Sets whether the column names should be quoted. If not set, the adapter will decide.
It is recommended to apply this config globally and to explicitly set it to False. If any of your columns contain special characters and spaces, it is simpler to rename them.
column_types: column_name: data_type (optional)
Defines data types for seeds columns according to the options provided by the adapter.
Needs to be configured using the full path of the seed:

If you’ve previously run “dbt seed”, you will need to run it again with the “--full-refresh” flag.
The recommendation is to use it only when required and should be otherwise omitted.
delimiter: “character” (optional)
Sets how values are separated in a seed.
The default value is a comma, and it should only be configured if you need to change that,
General configurations
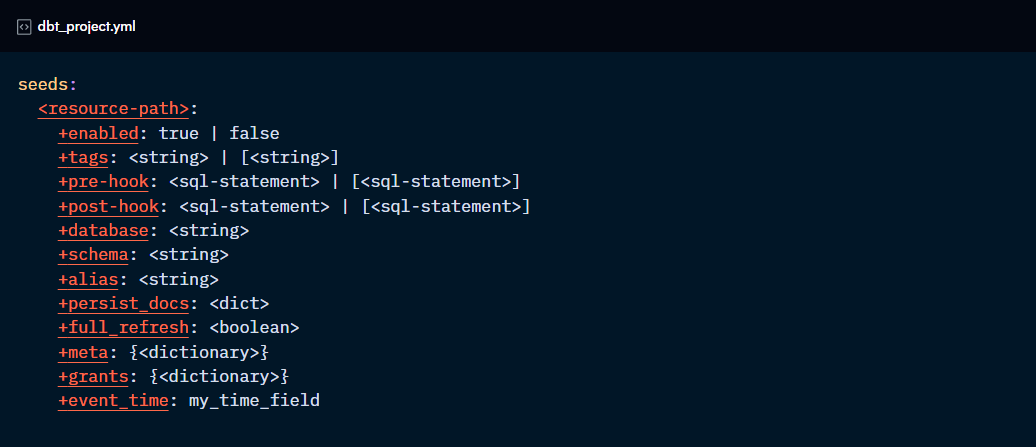
enabled: if set to False, dbt does not consider this resource part of the project.
tags: add common tags to resources to apply commands to all in one go using the “tag:” method.
pre-hook / post-hook: adds SQL statements that are run before or after the seed.
database/schema/alias: sets a custom database/schema/table name for the resource.
persist_docs: persists column and relation descriptions in the database.
full_refresh: sets whether a full refresh should take place whenever the resource is run, regardless of the “--full-refresh” flag being used or not.
meta: adds custom metadata for the resource to the manifest.json file and documentation.
grants: manages access to datasets. To be covered in future Checkpoints in more detail.
event_time: for seeds that track events, it defines the column where the time of the event lives for incremental materialisation, “--sample” flag, and CI/CD purposes.
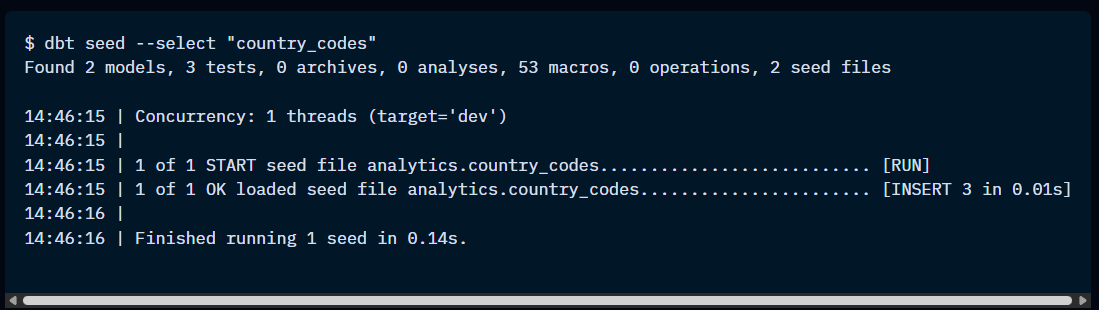
The dbt seed command
The “dbt seed” command writes the .csv files stored in the seed-path directory into the database. It supports the “--select” method.
Thanks for another interesting post!!Since command “dbt seed” writes directly in the database, in my team we consider a good practice to not directly use .csv files with the “ref” function but rather create staging models for every csv being used and call them with the “source” function.
This way we follow the dbt best practice that for each source (.csv file) we use one staging model.
The advantage is that any future change in the csv file goes through the staging models and doesn’t disrupt the DAG flow.