
Incremental materialisations
Digging deep into the definition and config for incremental models.
Part of the “Mastering dbt” series. Access to the full Study Guide. Let’s connect on LinkedIn!
Notes from this and this documentation.
We previously covered the more straightforward materialisation types. In this post, we are going to cover Incremental models, the different incremental strategies, how to set them up, and the extra configs available.
What are incremental models?
Definitions:
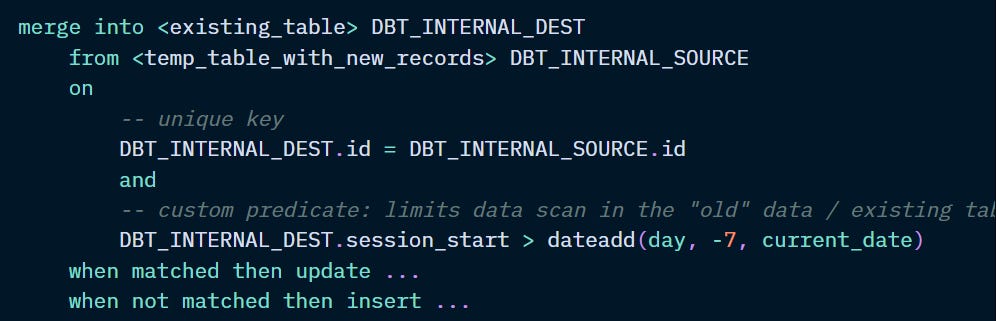
Compiled statement: “merge into”
Stored as: tables, that is, physical objects in the warehouse with rows of data.
When you run a model with this materialisation: dbt executes the SQL using a merge statement with criteria on which records to add or update.
Pros:
This materialisation limits the transformations only to rows that have been added or updated since the last run, which makes for a faster runtime.
Improves performance.
Cheaper in terms of computation costs.
Cons:
They require extra configuration and are considered an advanced feature.
Configuring incremental models
Basic configuration
Besides the “materialized” configuration in the dbt_project.yml or model, you also need to configure the incremental build within the model:
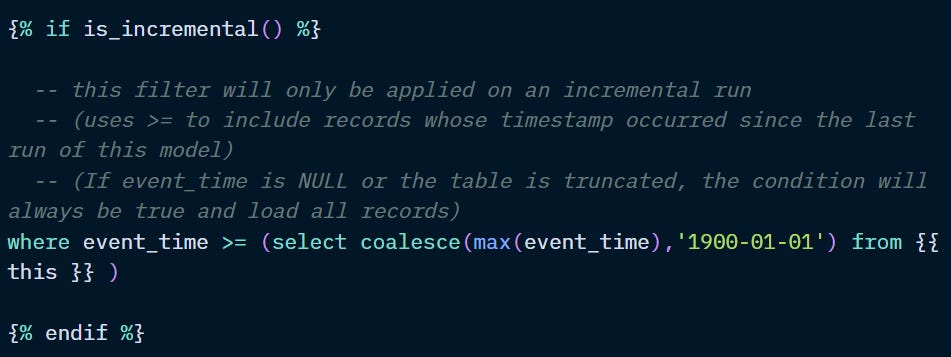
Above, we are telling dbt to only merge records for which the event_time column is greater than or equal to the maximum event_time record in the table {{ this }}.
The {{ this }} variable is a Relation and can be understood as the equivalent of a ref(‘<the_current_model>’).
So, basically, it looks at the table in its latest run state, checks the date of the latest record, and uses it as a benchmark. Then, for the current run, it will check the date of each record to see if it’s newer than the benchmark. If it is, it will merge the record into the existing table. If it isn’t, it will leave it alone or update it, depending on the configuration.
The positioning of this if statement can also impact the runtime and cost of running your model. For complex models, consider filtering the data as early as possible.
Incremental strategies
Your chosen strategy will define how dbt will handle new data streaming in and it will depend on:
the volume of data
the reliability of the unique_key
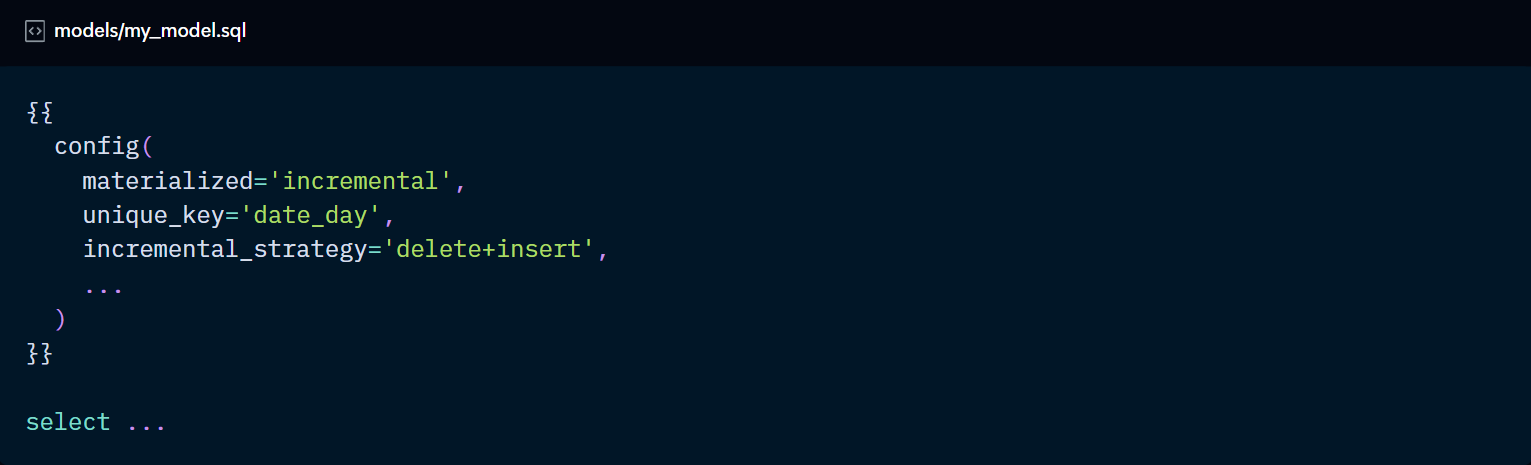
The “incremental_strategy” parameter is used to define the strategy and can be configured in the dbt_project.yml file or in the model itself:

Built-in strategies
There are 5 possible values for the incremental_strategy config:
append
delete+insert
merge
insert_overwrite
microbatch
There is also the possibility of creating custom strategies, but this is not part of the exam, so we will focus on the built-in strategies below.
1. Append:
Inserts new records without updating or deleting existing data.
When doing so, it does not check if the appended records are duplicates of existing ones, which could potentially result in duplicate rows. However, it is simple to implement and has low processing costs.
2. Delete+insert:
When a matching record is found for the unique_key, it deletes the entire row and inserts the new match. It also inserts new records.
This is useful when the unique_key isn’t truly unique or the merge strategy is not available for the used adapter. But not very efficient for large datasets.
3. Merge:
Inserts the records that don’t already exist and updates the existing keys. This is the same method as the SCD1: it overwrites records without tracking historical changes.
This prevents duplicates for existing records, but it can be expensive for large datasets as it scans the entire table to determine what to update or insert.
4. Insert_overwrite:
Replaces entire partitions with new data, rather than working in individual rows.
Obviously, it’s ideal for tables partitioned by date and useful for not requiring a full table rebuild.
5. Microbatch:
Designed for processing large time-series tables, it splits the data into periods (for example, daily and hourly) and updates/adds records in chunks. This ensures a faster run.
Additional configurations
Defining a unique_key
This parameter is useful to avoid duplicate rows and is a requirement for the “merge” strategy. Not defining it will result in an “append” behaviour.
It specifies a field (or combination of fields) that defines the grain of your model.
Like all primary keys, the column (or columns) defined as unique_key may not contain NULLs, so either use coalesce to replace nulls or create a surrogate key. Also, if your unique_key is not unique either in the target (existing) table or the new records, your run may fail.
Limiting the records to be scanned
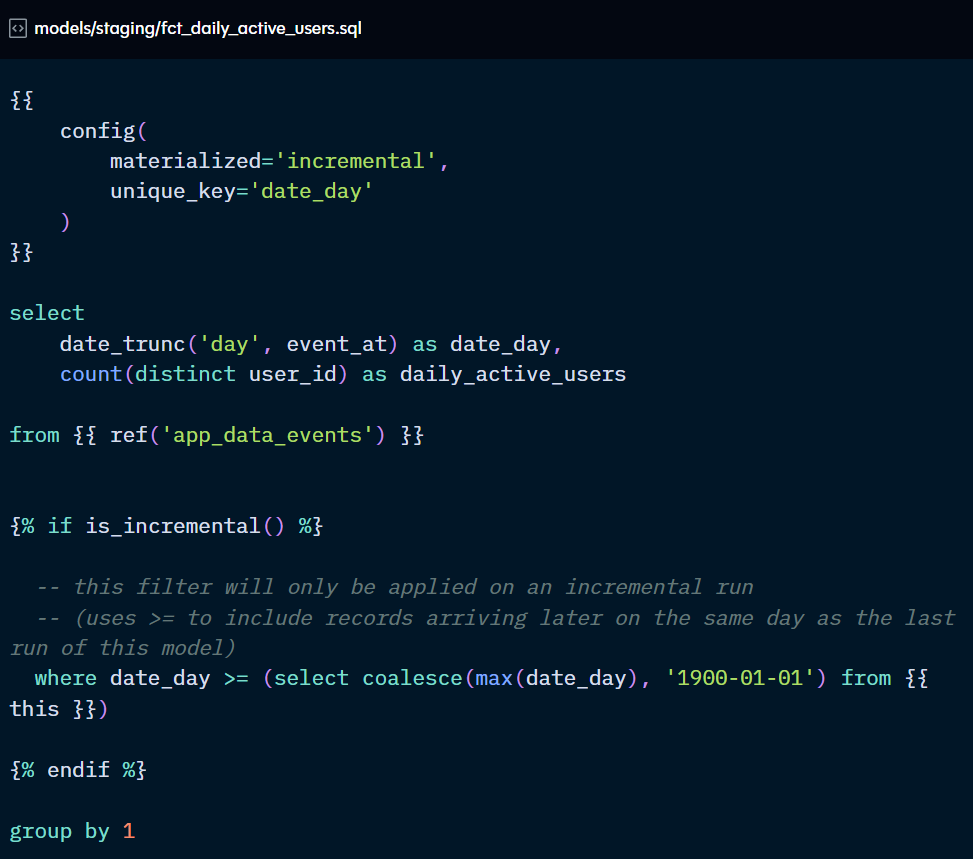
By default, the is_incremental( ) macro will scan the entire table for new records. However, if the volume of data is excessively large to warrant additional configuration, you can also limit the records to be scanned with the “incremental_predicates” parameter.
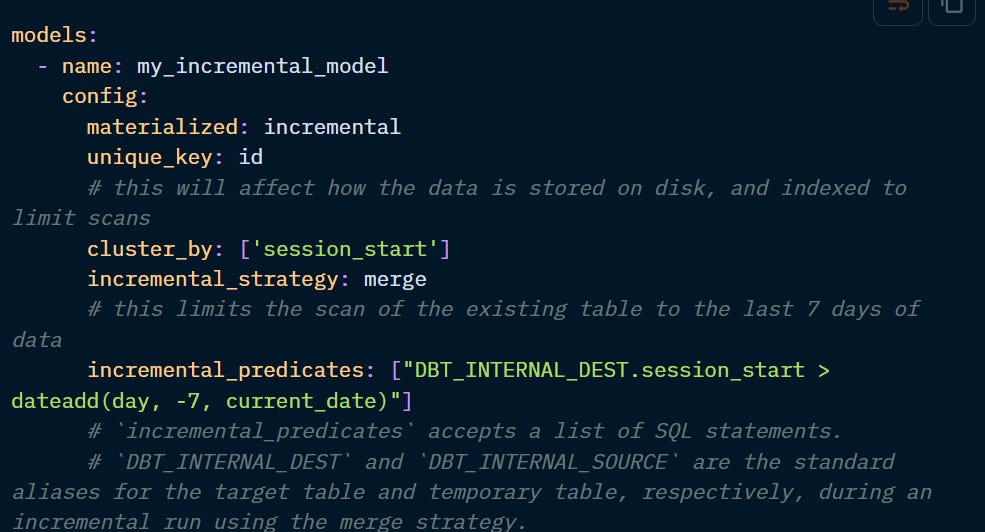
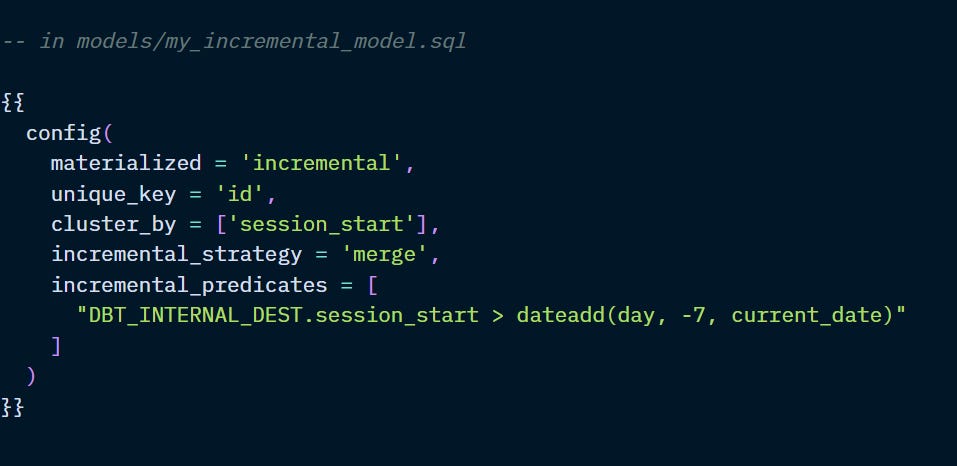
In both examples above, only the records from the latest 7 days of data will be scanned for new or updated records, rather than the entire table.
How do I rebuild an incremental model?
When you make changes to the logic of your incremental model, you may need to rebuild the entire table.
To do so, use the flag --full-refresh on the command line. It is also advisable to rebuild all downstream models. You can also use the full_refresh config at project or resource level, set to true or false, to override the use or absence of the --full-refresh flag.
What if the columns of my incremental model change?
Incremental runs only identify row-level changes and it does not detect or apply column changes. You can set up the “on_schema_change” config to tell dbt what to do when it detects the model’s schema has changed since the last run.
By default, when you delete a column and try dbt run, it will fail. And when you add a column, dbt run will not add the new column to the table.
It has 4 possible values:
ignore: maintains the default behaviour
fail: triggers an error message when the old and new schemas differ
append_new_columns: adds the new columns to the data but does not remove deleted columns
sync_all_columns: adds new columns and removes deleted ones, including data type changes.
Note that none of these configs will backfill data for existing records. To achieve that, a --full-refresh is required.