
Practice Project: Checkpoint 4 - Part 2
Let's add live data to our project and configure our first incremental model.
Part of the “Mastering dbt” series. Access to the full Study Guide. Let’s connect on LinkedIn!

Incremental materialisation is one of the trickier configurations of dbt. It requires attention to detail as the placement of the configs affects how and when the incremental rows will be processed.
I covered only the essentials in incremental materialisations in this post due to a limitation of my adapter’s free tier. I think a real-life scenario would present more challenges than I was able to replicate here.
Still, this is good practice to understand the intricacies of this type of materialisation and the many ways in which it can be configured.
Incorporating live data into our project:
So far, we have been working with static data in our Practice Project. Now, thanks to Leo Godin’s efforts in setting this fake database up, we are going to add live data.
Our project will now receive new orders every day. We will assume no new employees, products, or companies are added. Only new orders.
Setting up the new connection:
Godin’s data is hosted in a public BigQuery dataset that we can directly add as a source to our project. You can view documentation on the full dataset here.
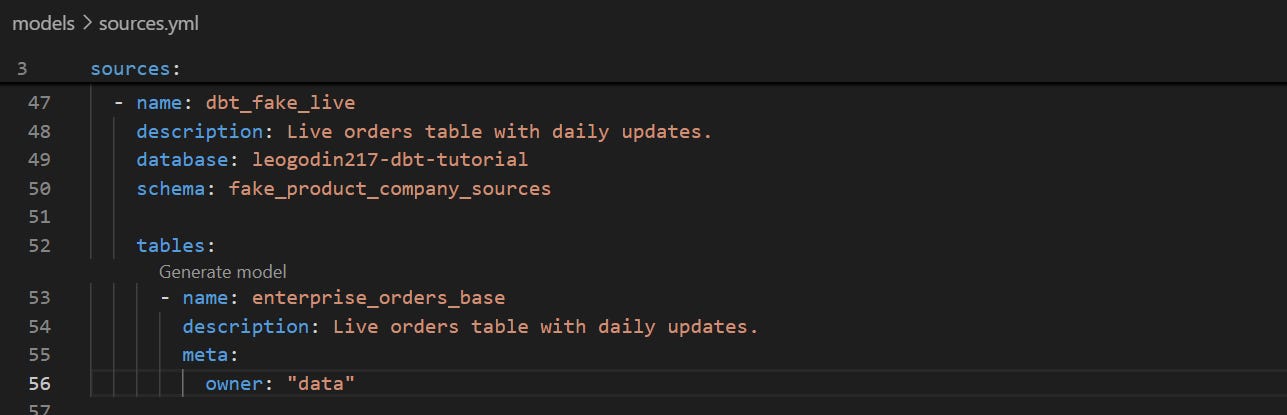
Replacing the source of our orders table:
Now, we are going to replace the orders source in the “stg_orders” model. Optionally, you can also remove the static orders table from the source.yml file or use the “enable: false” property to remove it from the project.
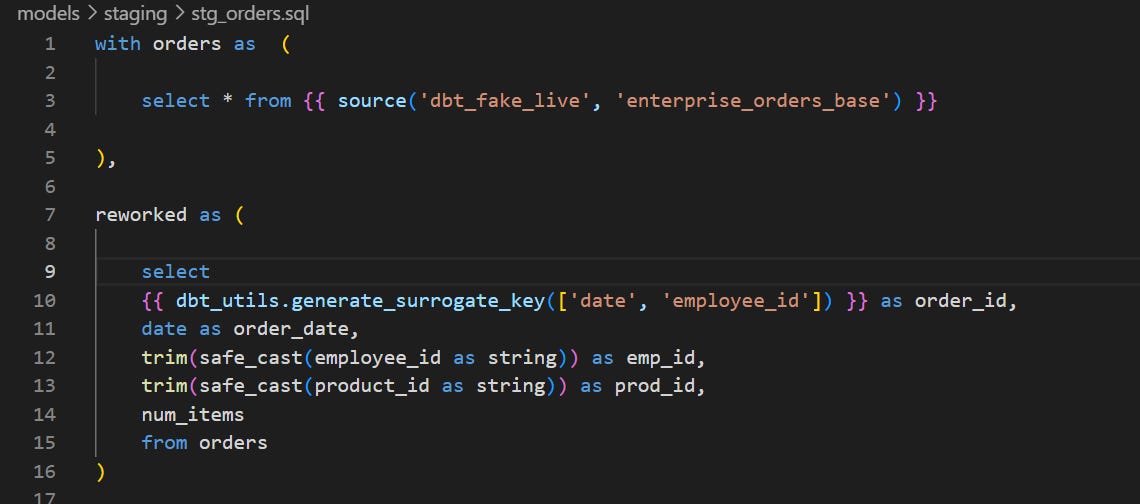
Configuring the incremental materialisation:
You want to add the incremental strategy in the layer where the heaviest transformations take place. This way, these costly operations will only be applied to new rows at each run.
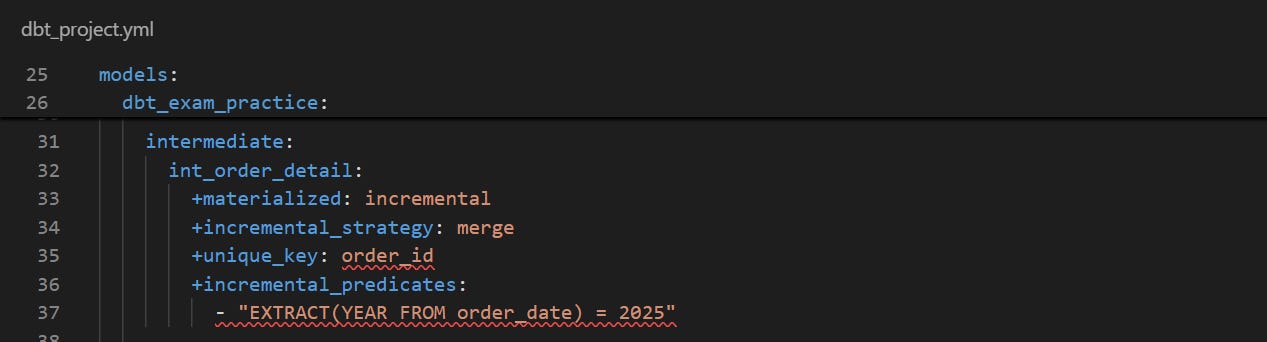
In our case, the optimal model is int_orders_detail. We are also going to implement a merge strategy and limit the scan of new records to orders from 2025. We are taking the assumption that orders from previous years never change.
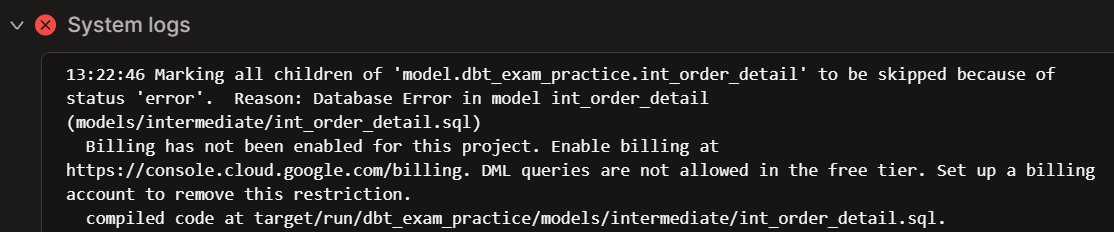
Please note that I’m working on BigQuery’s free tier in this project, which doesn’t support DML queries. Therefore, even with the correct configurations, the “dbt build” command will still fail. However, the logs will show us that dbt tried to implement the incremental materialisation.
dbt_project.yml configuration
According to the documentation, you can add the incremental configurations to the dbt_project.yml or the model itself.
Upon trying to build the models, the command fails and the logs show that dbt tried to run a DML query, but my adapter has billing disabled.
In-model configuration
Using a config block, we can set all the configs for the incremental materialisation in the block itself. Remember that this block can be placed strategically in the code (for example, after the data has been filtered).
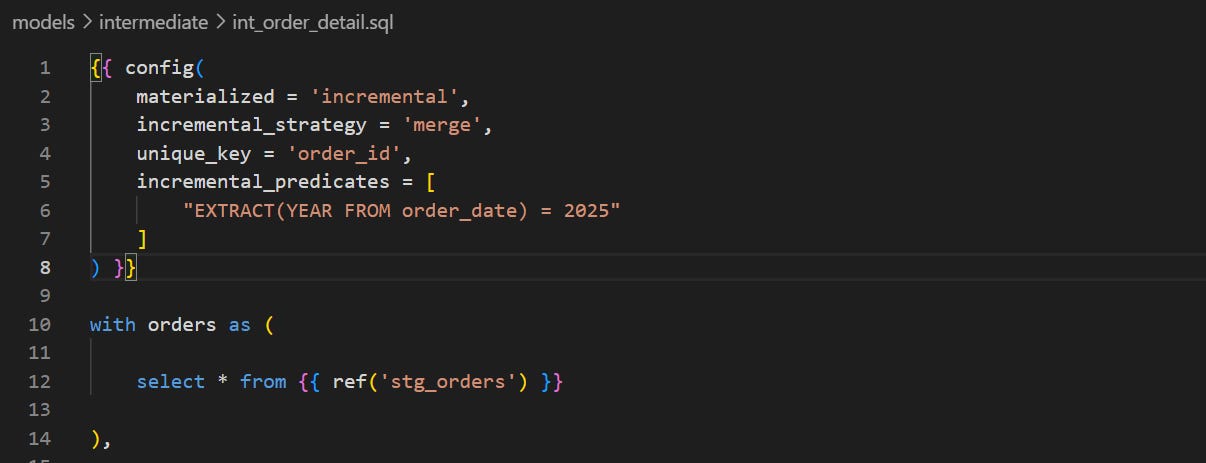
The logs are even more detailed in this case. You can see dbt tried to merge the new records, applied our predicates, and only searched for new records within orders from 2025.
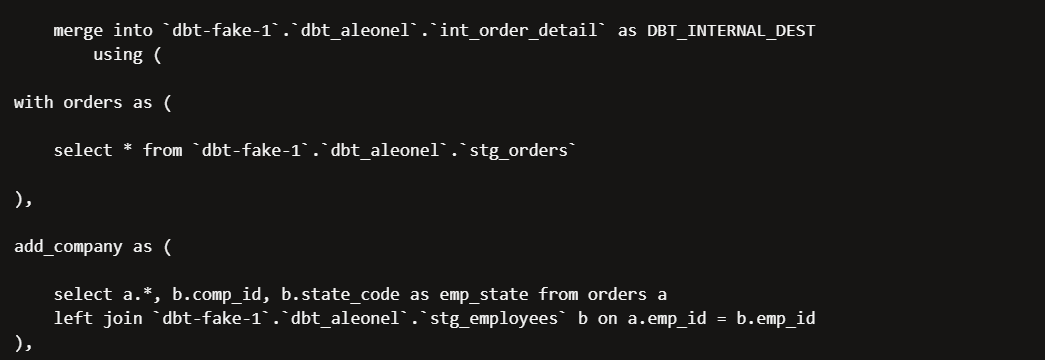
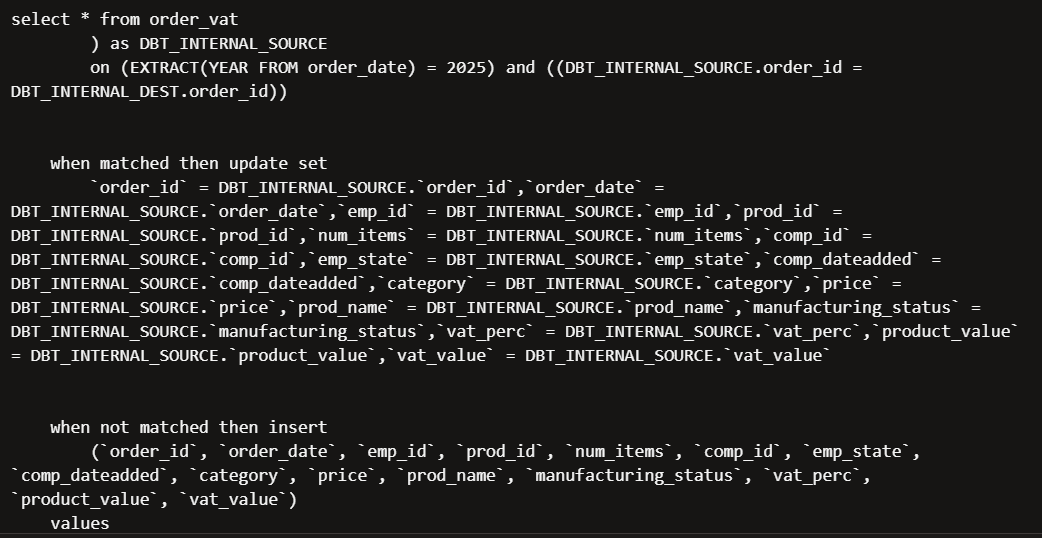
We can also apply a simpler configuration to your incremental materialisation using the is_incremental macro:
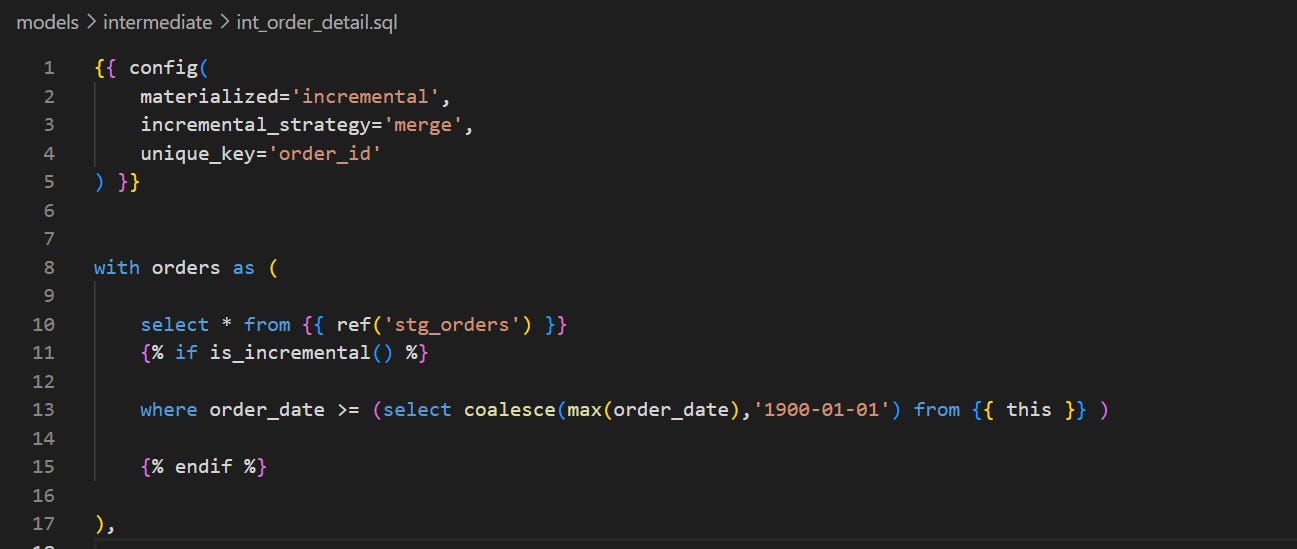
While incremental_predicates filter the rows that the warehouse will consider during the MERGE step, is_incremental( ) filters the rows selected from your source before the merge happens.