
What is a dbt model and how they can be configured
The key definition for models, how and where to configure them, and the available configs for this resource.
Part of the “Mastering dbt” series. Access to the full Study Guide. Let’s connect on LinkedIn!
Notes from this documentation.
Models are the first dbt resource we are going to cover in detail. Below, we are going through the definition of a model, how to configure them, and the available configurations.
The more advanced configs will be covered in more detail in future Checkpoints, but are cited here for familiarity.
What is a model?
A model is a SQL file that applies transformations to the data without it ever leaving the warehouse. When we execute “dbt build” these transformations are built into datasets following the instructions we give dbt in the form of model configurations.
It’s worth mentioning that while at practice stages we may work with a handful of models, in real life, companies operate with a complex structure of models.
Besides, while models are primarily written in SQL, dbt recently enabled the option to write Python models, a functionality that will be covered in future Checkpoints.
Configuring models
Models can be configured in 3 places, following the order of precedence of configs and properties:
Using a {{ config( ) }} Jinja macro directly in the model.
Using the “config:” property within a properties.yml file.
In the dbt_project.yml file under the “models:” key.
Within the .yml files, the most specific config in terms of directory will take precedence.
What happens when you change the config for a model?
For some of the configs below, it’s important to understand the steps behind the materialisation of a model:
If a model does not exist with the provided path, dbt creates the new model.
If a model exists, but has a different materialisation type, drop the existing model and create the new model.
If “- -full-refresh” is supplied, replace the existing model regardless of configuration changes.
If there are no configuration changes, perform the default action for that type (e.g. apply refresh for a materialized view or “create view as” for a View).
Determine whether to apply the configuration changes according to the
on_configuration_changesetting.
Available configurations
Model-specific configurations
These settings are only applicable to models and not to other resources.
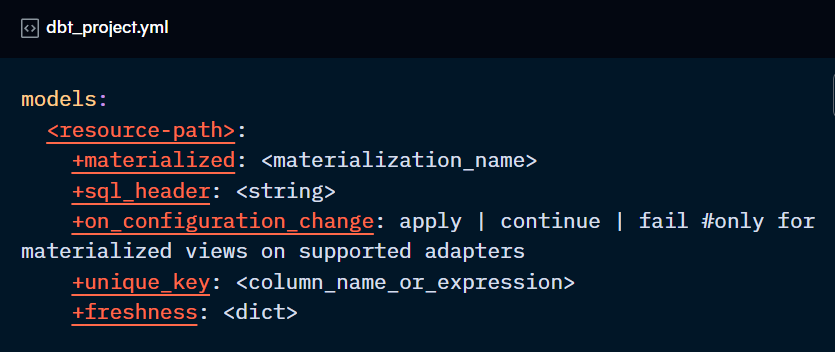
materialized:
Defines the model materialisation type.
sql_header:
Allows you to add a SQL statement before the “create table/view as” command, in the same query. Please note that pre-hooks have a similar functionality, but they place the statement in a separate query.
This config is useful for setting session parameters for Snowflake, for example.
There is also the “set_sql_header” macro, which does the same thing but with the added ability to include multi-line code.
on_configuration_change (for materialised views only):
For table, views, incremental and ephemeral models, dbt will manage any configuration changes by dropping the database object and recreating it.
However, for materialised views, the object is managed by the warehouse, not dbt. So, this config allows you to define what should happen when there is a change in the dbt configuration.
It has 3 possible configurations:
Apply (default): it drops and recreates the model with the new configuration.
Continue: it ignores the change and uses the previous configuration
Fail: the run fails and the model is not built.
unique_key:
Identifies the primary keys for incremental models and snapshots. It can be one or multiple columns.
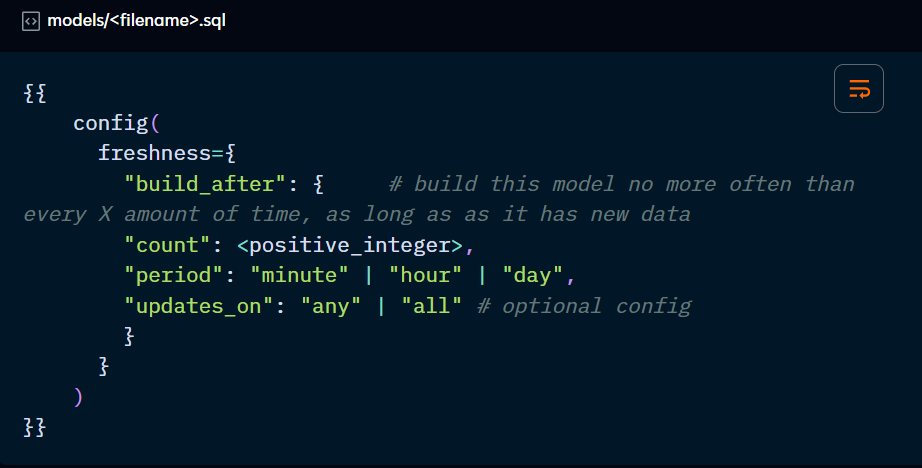
freshness:
Allows you to build models only when new data has been added to it or upstream. This is useful to save building models unnecessarily. It’s configured using the build_after parameter and its subparameters:
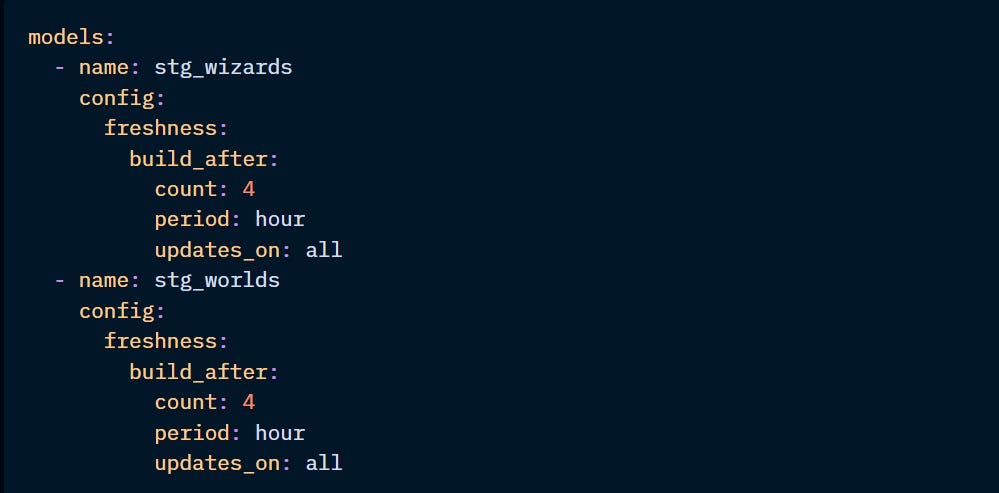
In the example above, the models will only update if:
new source data is available for all upstream models (if the “updates_on” was set to “any”, it would check if at least one upstream model has new data)
the two models were built more than 4 hours ago.
General configurations
Other configs can be applied to different types of resources, including models. They can be defined in the same places as model-specific configs and follow the same hierarchy.
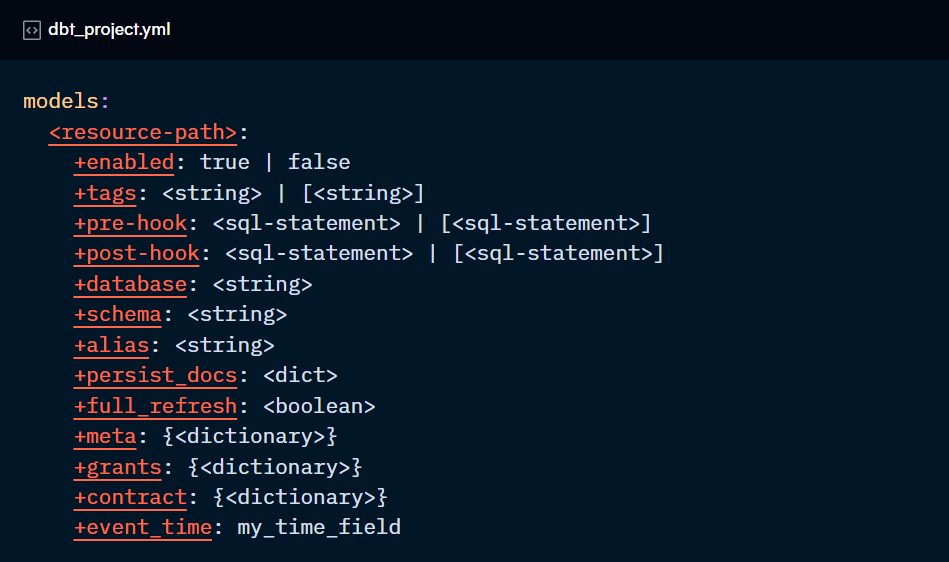
enabled:
An optional configuration to enable or disable a resource. If you want to exclude a model from a particular run, use the “- - exclude” node selector instead.
May be used for when you want to create your own version of a package model. You create the new version under the same name and disable the package model.
tags:
You can tag resourcers and use the tag in node selection. For example: “dbt run --select tag:events+” which selects all models with the “events” tag and its downstream models.
pre-hook & post-hook:
A separate SQL query or a macro to be run before (pre-hook) or after (post-hook) the model is run. Used when you want to run functionality that dbt doesn’t currently offer out of the box.
Remember to use the .render( ) method to resolve ref( ) or source( ).
Also note that hooks are cumulative: if you configure them both in the dbt_project.yml file and the model file, both will be applied in this order.
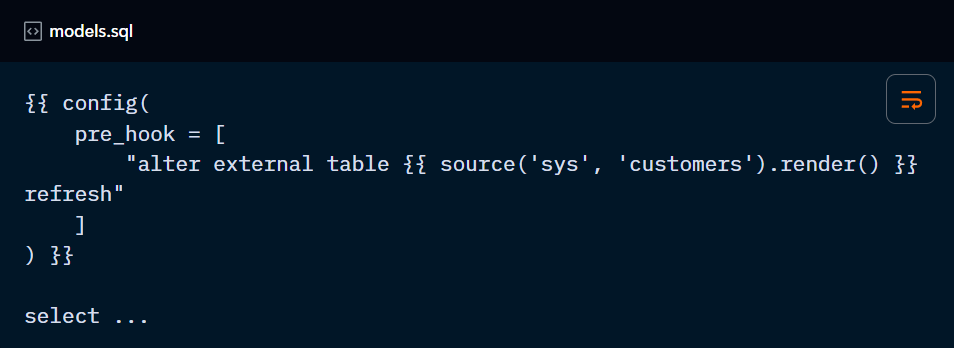
database & schema & alias:
Configure your model to be built into a database/schema other than the target ones. You can also set the name of the table in the database to be different to the model name by defining an alias.
persist_docs:
Allows you to send model and column descriptions set in dbt to the database. Adaptors will have their own limitations to this configuration.

full_refresh:
Configures whether a model will always or never perform a full refresh. If set to true, it will always perform a full-refresh.
If set to false, it will never perform it, even if you add the “- -full-refresh” flag to the selector. This is the recommended setup for large datasets so they never get fully dropped and recreated.
If not defined, it will follow the usage or not of the “- -full-refresh” flag.
meta:
Adds custom metadata to the manifest.json file that also appears in the documentation. It accepts pairs of values.

If set up in the model file, you can overwrite a standard attribute for that particular model.
docs:
Allows you to configure documentation for the models.
The parameter show can be changed from its default value (true) to false so it hides the model(s) from the documentation. Note that they will still appear in the DAG but with a “hidden” label.
You can also assign custom columns for the nodes using the node_color parameter. You’ll need to re-run “dbt docs generate” for the changes to take effect.
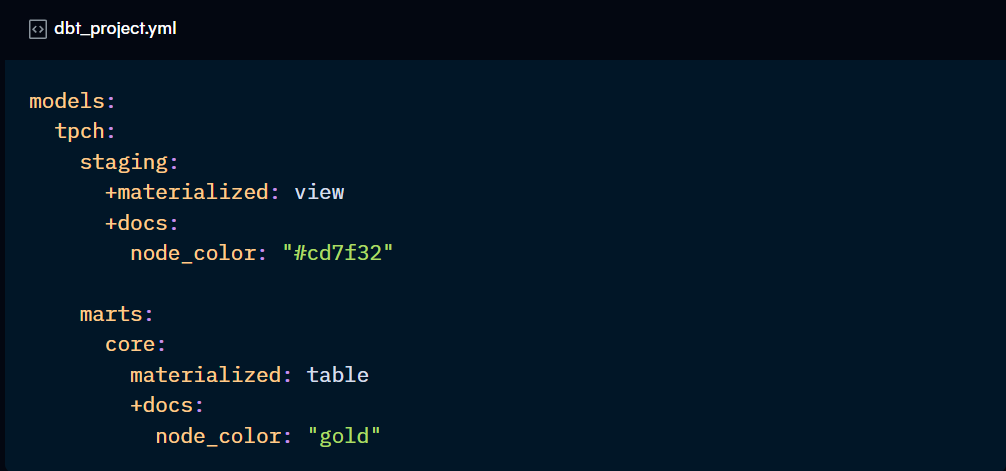
group:
You may want to include your models in a group if you want to restrict the models that can reference them (see access below). This is helpful for projects with multiple collaborators.

Besides assigning the group to the models, the group needs to be declared. They can be declared in the dbt_project.yml or in a groups.yml file, usually placed in the main models directory.
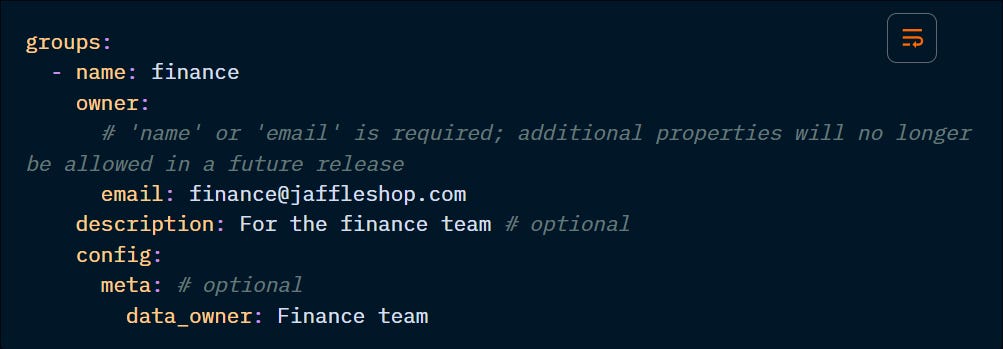
Notice how each group has a name and an owner, and can also hold the description property and meta config. This is what differentiates a group from a tag.
You can also select a group using the group method, for example: dbt run --select "group:finance"
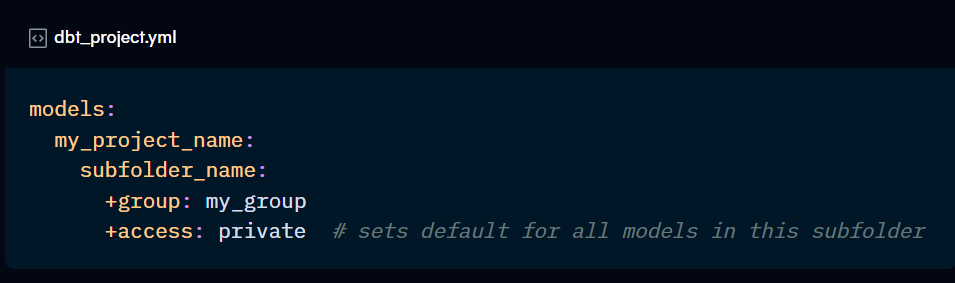
access:
This defines the access level for the models you are configuring. This affects which models can ref the model(s) you are configuring.
It accepts 3 possible values:
private: can only be referenced by models in the same group.
protected (default): can be referenced by all models within the package/project.
public: can be referenced by any project, group or package. Requires a production job rerun to apply the change.
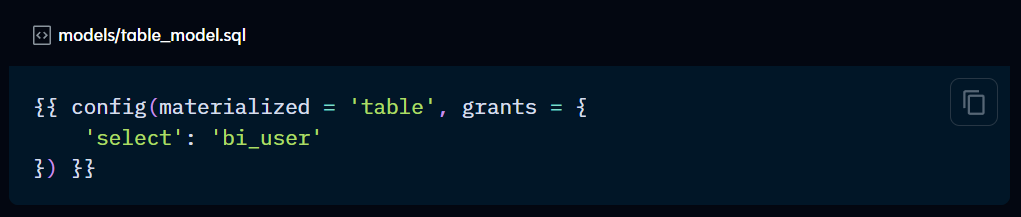
grants:
Grants will be covered more in-depth in future Checkpoints, however, put simply, this config allows you to set specific permissions to specific users within dbt.
This functionality is only available for tables and views. Use hooks if you need to apply permissions to other database objects.
contract:
Contracts will also be covered in the future, but it is basically a way to ensure your model is following certain conditions that you set up, like column names, data types, and other constraints.
This ensures that you or other people that don’t break rules that could cause your pipeline to break.
event_time:
This configuration is required for certain incremental materialisation strategies, the “- -sample” flag and advanced CI/CD deployments. We will cover this in future Checkpoints.
Warehouse-specific configurations
These won’t be covered by the exam, but you can see a full breakdown of these here.