
The 4 key dbt commands and node selectors
Defining the key commands to turn your models into tables and how to select specific resources in the command line.
Part of the “Mastering dbt” series. Access to the full Study Guide. Let’s connect on LinkedIn!
Notes from this documentation.
On dbt, we make use of commands to execute certain actions, including turning your models into objects in your data warehouse. Additionally, sometimes we need to apply these actions to selected resources to save runtime and compute costs.
Below, we will cover the 4 key commands involved in transforming a model into a table in the database and how to apply these commands to specific resources.
The 4 key commands of a project’s lifecycle
For your models to become data in the warehouse, dbt needs to parse your project files, compile the code, and execute them. Each of these steps has specific commands associated with it, although you don’t necessarily need to run them all individually.
Let’s cover these steps and their commands:
dbt parse:
Reads all the project files (models, macros, .yml files, seeds, sources, snapshots, tests)
Validates syntax (eg, bad YAML, invalid configs)
Builds the JSON manifest (a JSON representation of your DAG and all resources)
Builds the dependency graph (DAG)
It does not compile SQL or connect to the warehouse
Useful for: checking config and errors without hitting the warehouse
dbt compile:
Includes parsing.
Renders Jinja + macros + refs into raw SQL
Saves the results in the “target/” directory
It does not send anything to the warehouse so there’s no compute cost
Useful for: debugging code and validating complex Jinja and macros. It also works to compile analysis files, which will be covered in future Checkpoints
dbt run:
This command has a dedicated post
It includes parsing + compilation
Executes the models in the project (does not execute tests, snapshots, or docs) in the order of dependency in the DAG
Materialises the models using the configured strategy
Useful for: creating the objects in the data warehouse
dbt build:
It includes parsing + compilation + run
Runs all resources in the DAG order: models, snapshots, seeds and tests
Useful for: running tests, seeds, etc, alongside the models in one command
If you use the “- -select” flag: it builds the selected models and their upstream dependencies, as well as seeds/snapshots/tests needed for those models.
Applying commands to specific resources
Besides the commands, we can also make use of flags, selection methods, graph operators, and set operators to narrow down the resources we want to affect.
After reading the flag used, dbt starts gathering the resources following this order:
selection methods
graph operators
set operators
Flags
The available flags are: “- -select”, “- -selector”, “- -exclude”, and “- -resource-type”
- -select or -s: allows you to specify a subset of nodes to execute. You can select a resource by name, path, or using methods like “tag:”
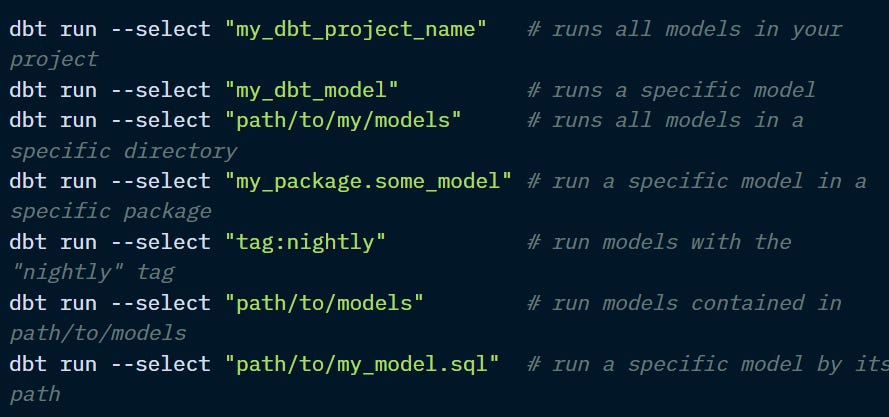
- -selector: when you need several criteria for the selection of the models that will need to be reused, consider using a yaml selector.
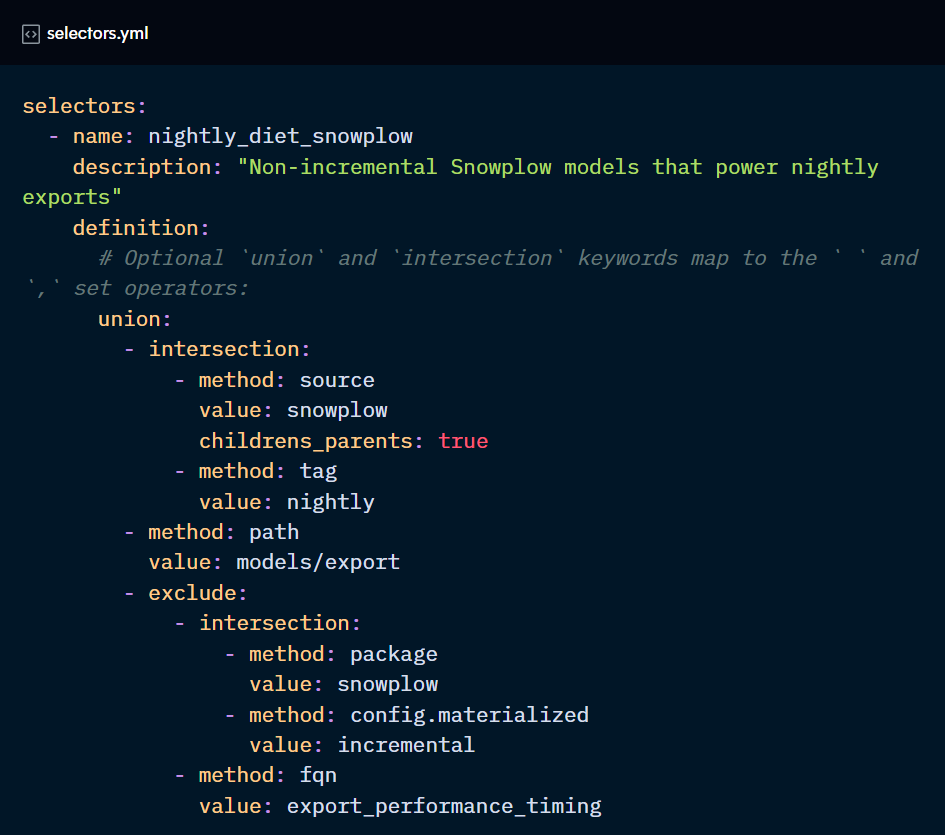
Note that, in this context, the exclude flag works slightly differently. It gets applied last, so dbt will gather all the resources following the other criteria and then apply the exclude method.
Also, “selector” is a method in itself, so you can reuse another selector.
- -exclude: used in conjunction with the select flag to exclude certain resources from the selections.
- -resource-type or -r: limits a command to certain types of resources. Only applicable to the build and list (covered below) commands.
Selection methods
Selection methods allow you to choose resources based on certain properties and characteristics. Here is a list of available method:
access: selects models based on their access level. Possible values: public, private, protected.
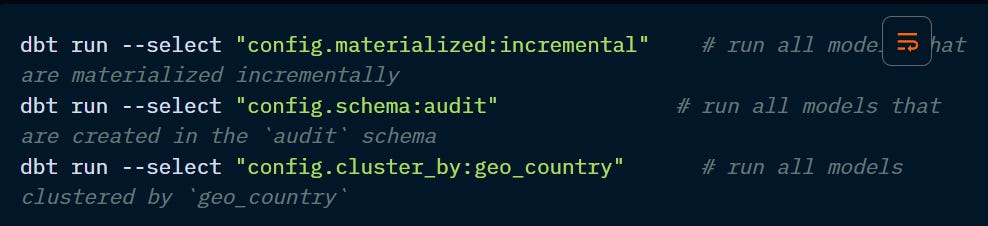
config: matches a specified node config.
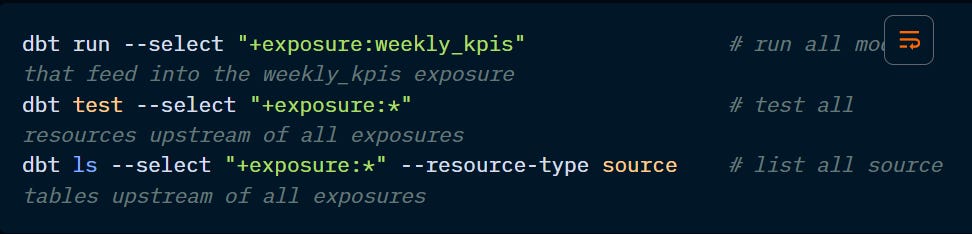
exposure: selects the parent resources of a specified resource. To be used with the + operator.
file: selects a model by its filename, including the extension .sql.
fqn: stands for “fully qualified name” which is composed of the project name, subdirectories, and the file name without the extension.

group: selects models within a group.
metric: selects parent resources of a specified metric. Used in conjunction with the + operator.
package: selects models defined within an installed dbt package or the root project. You can use “package: this” to target the current project. Can be implicit.
path: selects models under a specific path. Can be implicit.
resource_type: select nodes of a particular type, similarly to the flag.
result: selects models based on their result status from a prior run. Possible values: fail, error. Can be used with the + operator.
saved_query: selects saved queries.
semantic_model: selects semantic models.
source: selects models from a specified source. Used in conjunction with the + operator.
source_status: selects models based on the freshness status of their sources. Possible values: fresher and stale. To be used with the + operator and requires the freshness config to be set up.
state: this is a complex and powerful method that will be covered in future Checkpoints.
tag: selects models based on a tag.
test_name: select tests based on the name of the generic test. Data tests will be covered in future Checkpoints.
test_type: selects tests based on their type. Possible values: unit, data, generic, singular.
unit_test: selects unit tests. Can be “unit_test.*” for all tests or specify a test name.
version: selects versioned models based on their identifier and latest version. Possible values: latest, prerelease, old, none.
Graph operators
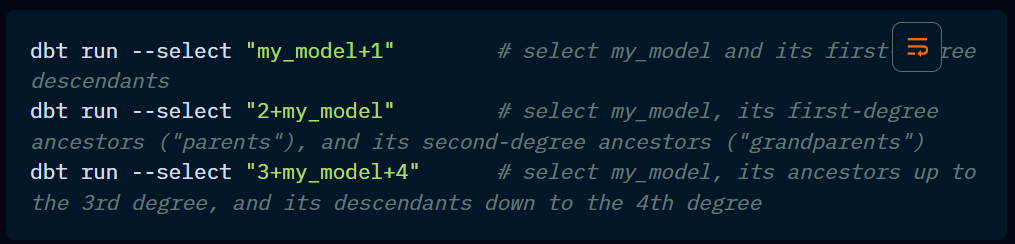
The + operator: the + operator allows you to include upstream and downstream models in your command.

You can also specify how many models downstream and/or upstream you’d like the command to apply to.
The @ operator: by using the @ operator, you can include all the models necessary for the successful build of the model selected.

In the example above, the selector @snowplow_web_page_content would run all 3 models shown.
Set operators
Unions: this allows you to run multiple groups of models.
In the example below, the models run would be: snowplow_sessions, all of its upstream models, fct_orders, and all of its upstream models. The whitespace between the model names is what makes it a union.

Intersection: if instead of whitespace, you use a comma between the models, dbt will run only the models included in both arguments.
The example below would run all the models under the marts.finance directory that are also tagged as nightly.
