
Interpreting logs and fixing common errors
Learn how to read the event logs and how to investigate common errors.
Part of the “Mastering dbt” series. Access to the full Study Guide. Let’s connect on LinkedIn!
Notes from these documentations: events logging and debug errors.
In this post, we are deep-diving into the logs generated by dbt when a command is run and how to debug eventual errors.
We covered all the common errors, but you can see more potential issues in the guide’s FAQs.
Events and logs
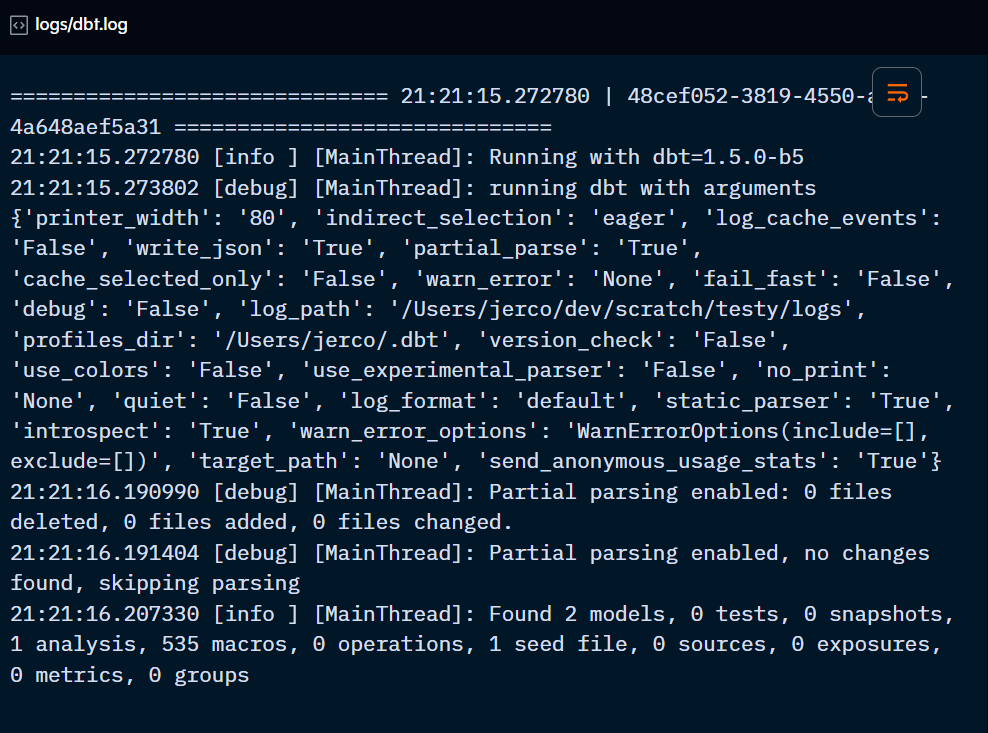
As dbt runs, log messages are generated with the events that took place. These logs are written into two places: at the command line terminal (stdout) and in a debug log file (logs/dbt.log).
The debug log file enables detailed debugging of errors when they occur, while the command line messages are more top-level.
Structured logging
On dbt-core, all events have a structured schema defined in types.proto using protocol buffers. This ensures that logs and events are consistent, typed, and efficient to process.
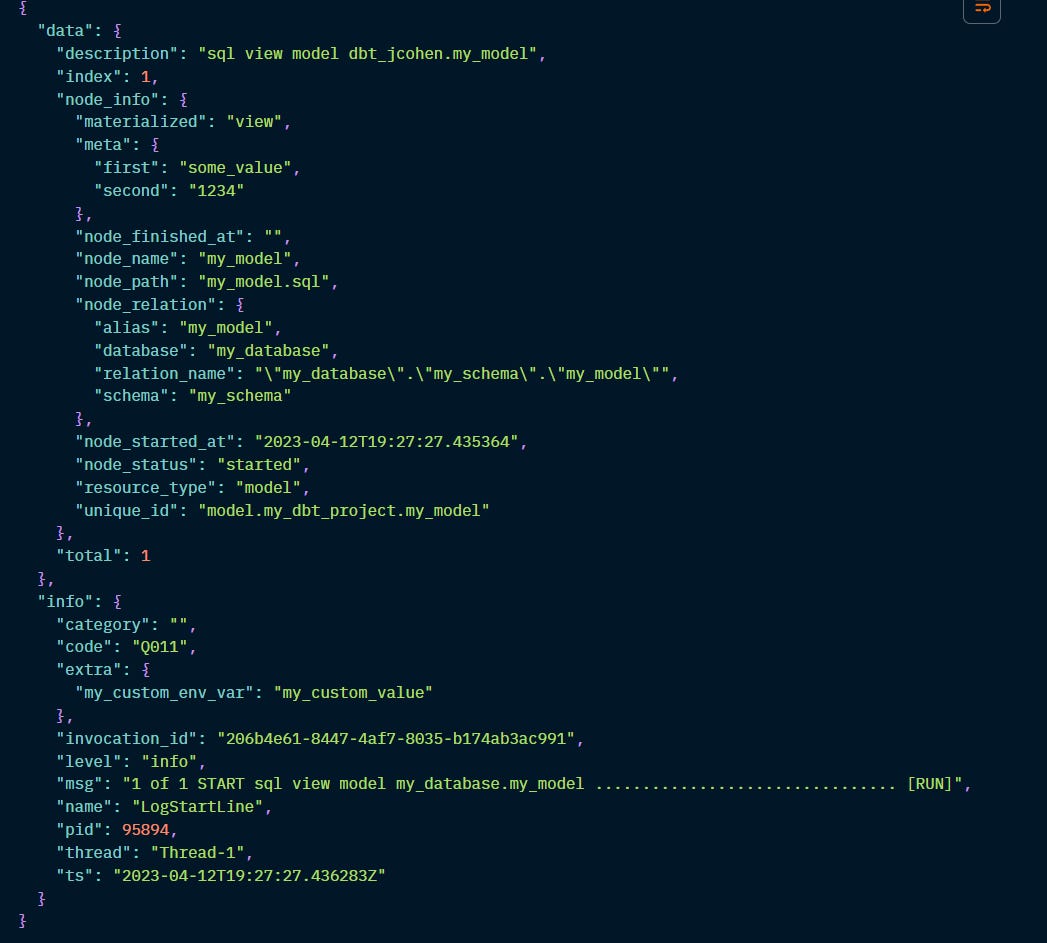
Every event has two top-level keys:
info: information common to all events
data: additional structured data specific to this event. A “node_info” field is generated for specific resources.
Info fields:
code: event identifier
extra: custom environment metadata based on environment variables
invocation_id: invocation identifier
level: the log level (debug, info, warn, error)
log_version: version
msg: human-friendly log message
name: name for the event type, matching the proto schema name
pid: process id
thread_name: the thread in which the log message was produced
ts: when the log line was printed
node_info fields:
materialized: view, table, incremental, etc
meta: user-defined meta dictionary
node_finished_at: timestamp when node processing completed
node_name: name of the resource
node_path: file path to the resource
node_relation: nested object containing this node’s representation, in terms of database, schema, alias and full relation_name.
node_started_at: timestamp of when the node processing started
node_status: RunningStatus (while running - possible values: started, compiling, executing) or NodeStatus (when finished - possible values: success, error, fail, warn, skipped, pass, runtimeerr)
resource_type: model, test, seed, snapshot
unique_id: identifier for the resource.
Debug errors
General process of debugging
read the error message
inspect the file that caused the issue
isolate the problem - for example, by running one model at a time or undoing the code.
get comfortable with compiled files and the logs
target/compiled: contains select statements that you run in the query editor
target/run: contains the SQL dbt executes to build your models
target/dbt.log: contains all the queries run and additional logging
if you’re stuck, ask for help in the community.
Types of errors
Runtime Error:
At the initialise stage, dbt checks that this is a dbt project and that it can connect to the warehouse. If you’re using the IDE, you’re unlikely to encounter these errors.
Not a dbt project:
Check that you’re in the right directory.
Check that you have a file named dbt_project.yml in the root directory.
Could not find profile

Check the “profile:” key in your dbt_project.yml.
Check that it matches the profile set up in profiles.yml.
Failed to connect

Check that the credentials in the profiles.yml file are correct.
If you update the credentials, run “dbt debug” to check that you can connect.
Invalid dbt_project.yml file
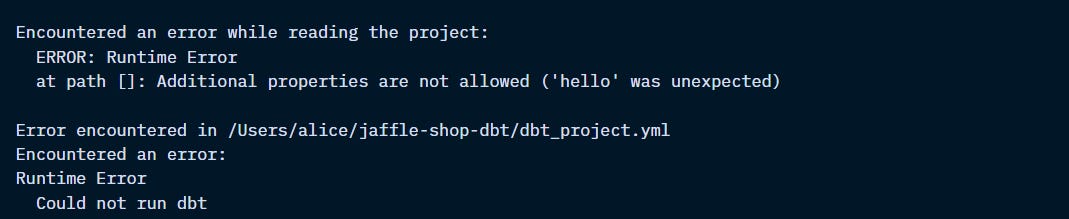
Open your dbt_project.yml file and check the offending key.
If the key is being used correctly, check that you are using the latest version of dbt.
Compilation Error:
At parsing, dbt checks that the Jinja snippets in the .sql files are valid and that the .yml files are valid. If you’re using the IDE, the error often shows as a red bar in the command prompt. For dbt Core, they won’t get picked up until you run “dbt run” or “dbt compile”.
Invalid ref function

Open the models/customers.sql and look for the reference to stg_customer
Ensure this has the same spelling as the file stg_customer.sql
Invalid Jinja

This error can happen due to a lacking {% endmacro %} tag, forgetting to close a }, or closing a for loop before closing an if statement.
Invalid YAML
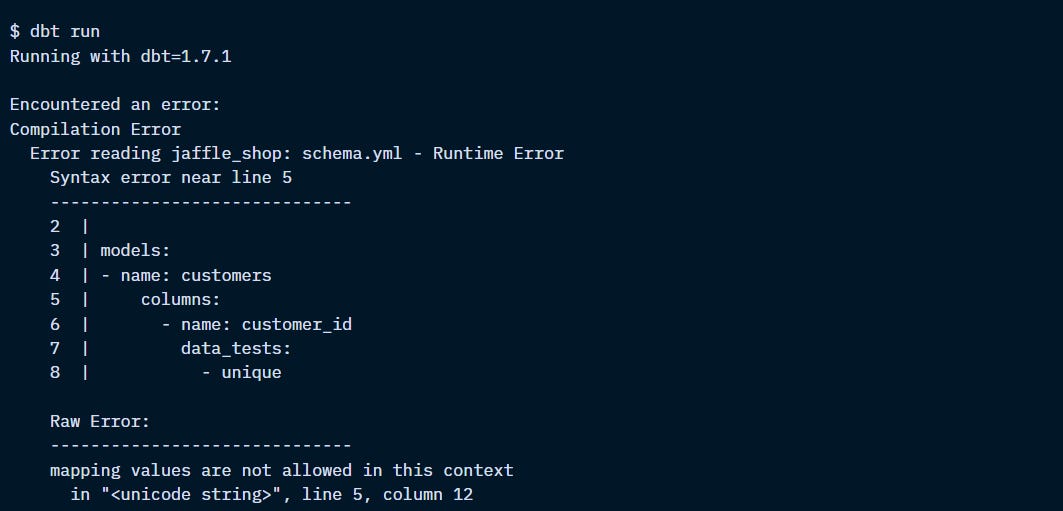
Usually, it’s to do with indentation.
Incorrect YAML spec

Here, the YAML structure is right but there is a key that dbt doesn’t recognise.
Open the file and search for the offending key.
If you’re using a valid key, check that you’re using the latest version of dbt.
Dependency Error:
Compiles the dependencies into a graph and checks that it’s acyclic.
It means the DAG is not acyclic.
Check and update the ref functions
If you need to reference the current model, use the {{ this }} variable.
Database error:
Happens at SQL execution when dbt runs the models.
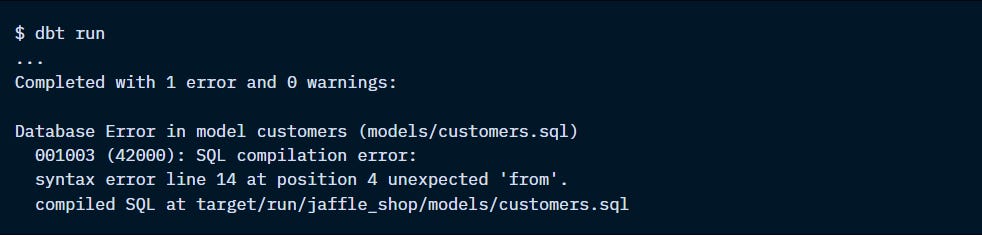
These errors come from the warehouse and are passed on by dbt.
90% of the time, it’s a mistake in the SQL. It can also be due to “behind-the-scenes” queries, like introspective queries to list objects, queries to create schemas, hooks, or merge/update/insert statements in incremental models.
Open the model and the compiled SQL in the target directory and compare them side-by-side.
Try to Preview the model and isolate the error.
Check the logs if you need to investigate further.